Logistic Regression
The logistic regression model is also one of the most popular models in machine learning for performing classification ( predicting the values of a qualitative variable based on predictors ). It is a parametric technique - the model must find the best parameters based on the data -.
This technique is used to adjust the relationship between a qualitative variable ( dependent variable ) and a set of predictors - independent variables - which must be quantitative variables or qualitative variables transformed into quantitative variables ( one-hot encoding or discrete variable digitization ).
The operation of logistic regression is almost identical to linear regression except that it uses a sigmoid function. Like linear regression, we assume that and are dependent, meaning that knowing the values of improves the knowledge of the values of . Therefore, there is a correlation between and - as a reminder : the more a variable is correlated ( positively or negatively ) with the variable , the more important it is for our model because we say it is « discriminant ». – see ( correlation ).
Logistic regression does not directly predict a qualitative value but a probability that a new record belongs to a class.
Some of the diagrams and concepts presented here are inspired by the Machine Learning course by Andrew Ng, a program created in collaboration between Stanford University Online Education and DeepLearning.AI, available on Coursera. Find the original course here: Machine Learning by Andrew Ng.
Linear vs Logistic
When we talk about regression, it refers to any process that tends to find relationships between variables.
Linear regression seeks to establish a linear relationship between the dependent variable (y) and the explanatory or independent variables () ( predictors ). Example of simple linear regression : if the car’s age increases by 1 year, the price will be impacted by ( according to the coefficient and the origin of the line ).
Logistic regression also seeks to establish a relationship between the dependent variable (y) and the explanatory or independent variables () ( predictors ) but uses a logistic function ( logit ) to obtain a value between and , which is the probability that a new record belongs to a class. For example, if the car’s age increases by 1 year, the probability that it breaks down will increase or decrease depending on the coefficient associated with age in the model.
One uses a linear function while the other uses a sigmoid function which, through an underlying linear function, models a probability.
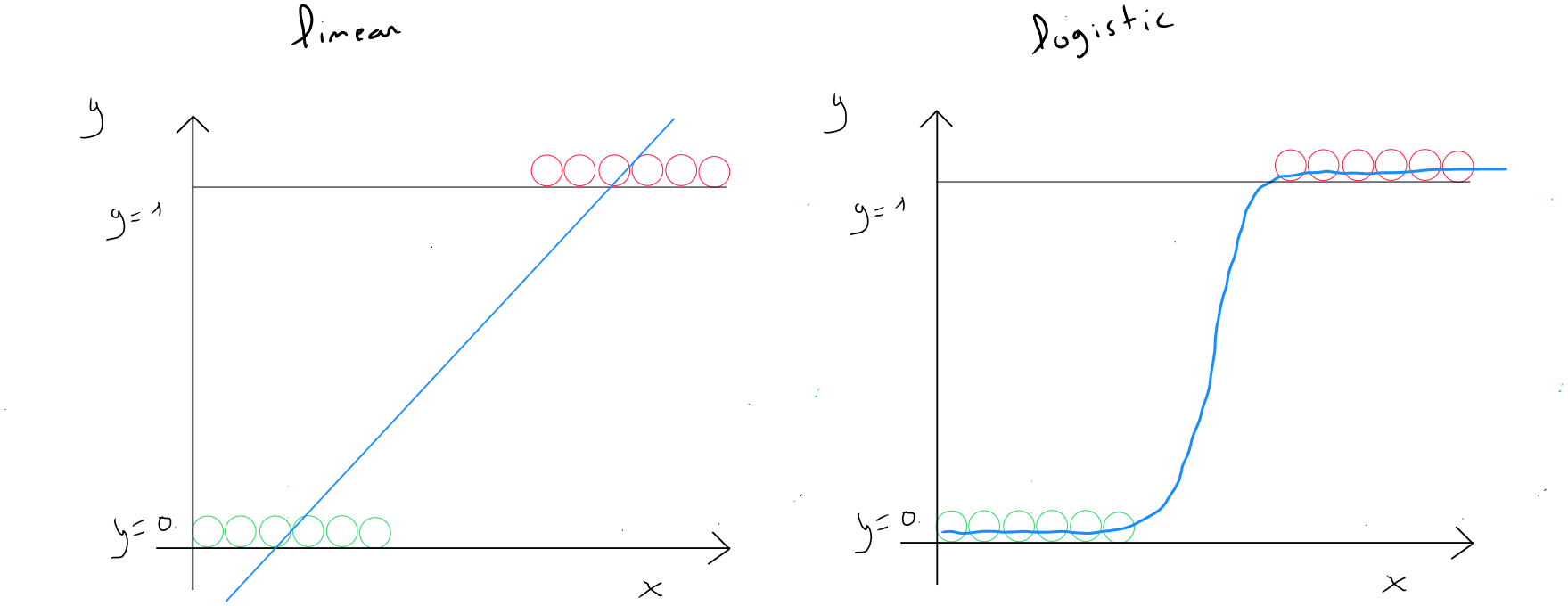
Why Not Use Linear Regression ?
Let’s take the example of a classification with two values : or . We have a distribution of values for both cases. If we use linear regression and draw the line, we could, in the example illustrated below on the left, consider that linear regression does a correct job, assuming we define a threshold of 0.5 to say that any value equal to or greater than equals ( class 1 ) and any value below equals ( class ). We see in the left graph that all values to the right of the perpendicular to have a threshold greater than or equal to and thus .
If suddenly, we have a record where the value of is much higher ( right graph – purple dot ), in this case, the slope of the line is modified, and we see that the model would predict some values greater than or equal to the threshold as belonging to class .
Therefore, we need to use a function that allows us to obtain a curve with the particularity of applying a linear form in a sub-function when values increase exponentially, but that would be flat at the beginning and end so that the values always remain between and . Specifically, it is an S-shaped function to ensure that possible values are between and .
Sigmoid Function
The sigmoid function - logistic function - is an S-shaped mathematical function that transforms any value into a number between and .
or
represents the linear sub-function. Just like linear regression, the logistic regression algorithm has training data, i.e. and , and based on this information, it must identify the parameters through a cost function and the gradient descent algorithm to find the local optimum. Once the parameters are identified, the sigmoid model outputs a value between 0 and 1 – a probability – which is transformed into a class based on a threshold definition ( usually ).
When rewritten in detail, the formula for gives us this :
and therefore the formula for the sigmoid function :
or
If we break down the formula :
- is the output of the sigmoid function, which gives us a value between and ;
- is the input to the function - which contains the parameters identified by the gradient descent algorithm based on the training data -. also requires new values of to predict a probability ;
- is Euler’s constant ( approximate value of ) and plays a crucial role in obtaining the S-shape ;
No matter the value of , the negative exponent of Euler's constant in the denominator will ensure that :
- if is a very large positive value , the sigmoid function will approach a maximum of ;
- if is a very large negative value , the sigmoid function will approach a maximum of ;
Sigmoid function in Python
def sigmoid(z):
g = 1/(1+np.exp(-z))
return g
# (z = np.dot(X[i],w)+b) - define later in the cost function
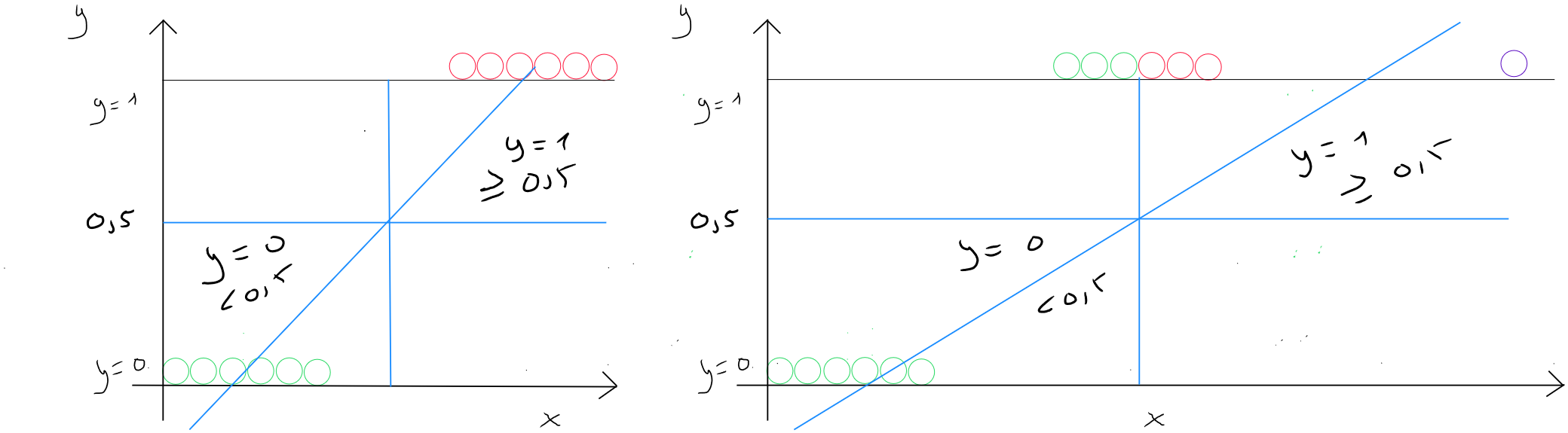
Decision Threshold
Logistic regression allows us to output a value between and from the function , and we, as data scientists, must define the threshold for class or class . In the literature, the threshold of is often mentioned, such that if the prediction value is , then , and if the prediction value is , then .
Linear Threshold
In the case of a linear decision based on two predictors ( ), we could represent the data as follows (diagram below) for values where , which corresponds to
To simplify the example, let's define 1 for and , and -3 for .
The linear decision threshold in this case would correspond to the moment when : as this threshold would be neutral in defining whether (red cross) or (blue circle).
In our case, since and are both 1 and is -3, we can rewrite the equation as follows : . Therefore, .
The formula for the linear decision threshold corresponds to the initial formula for logistic regression :
or
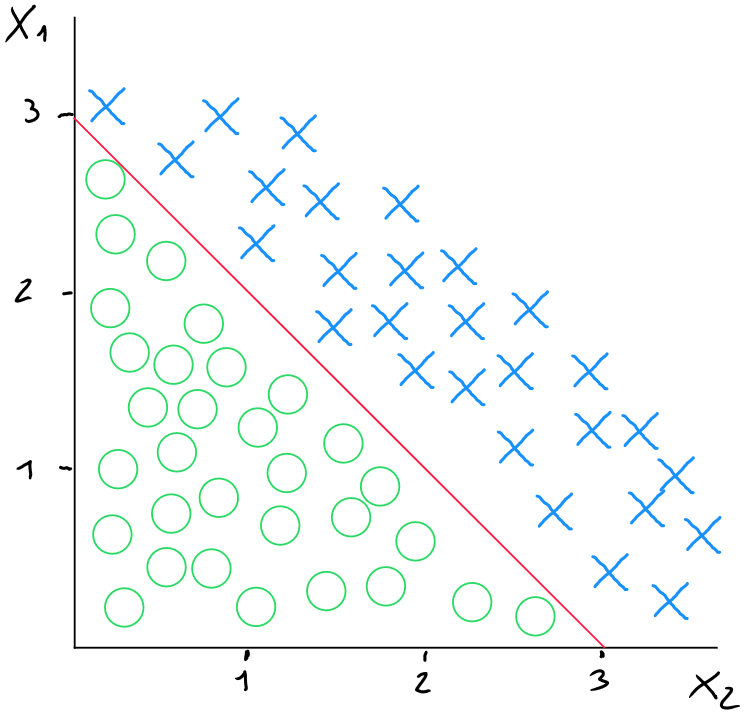
Non-Linear Threshold
As we discussed for polynomial regression in the chapter on linear regression, we may encounter cases in logistic regression where the data separation is non-linear.
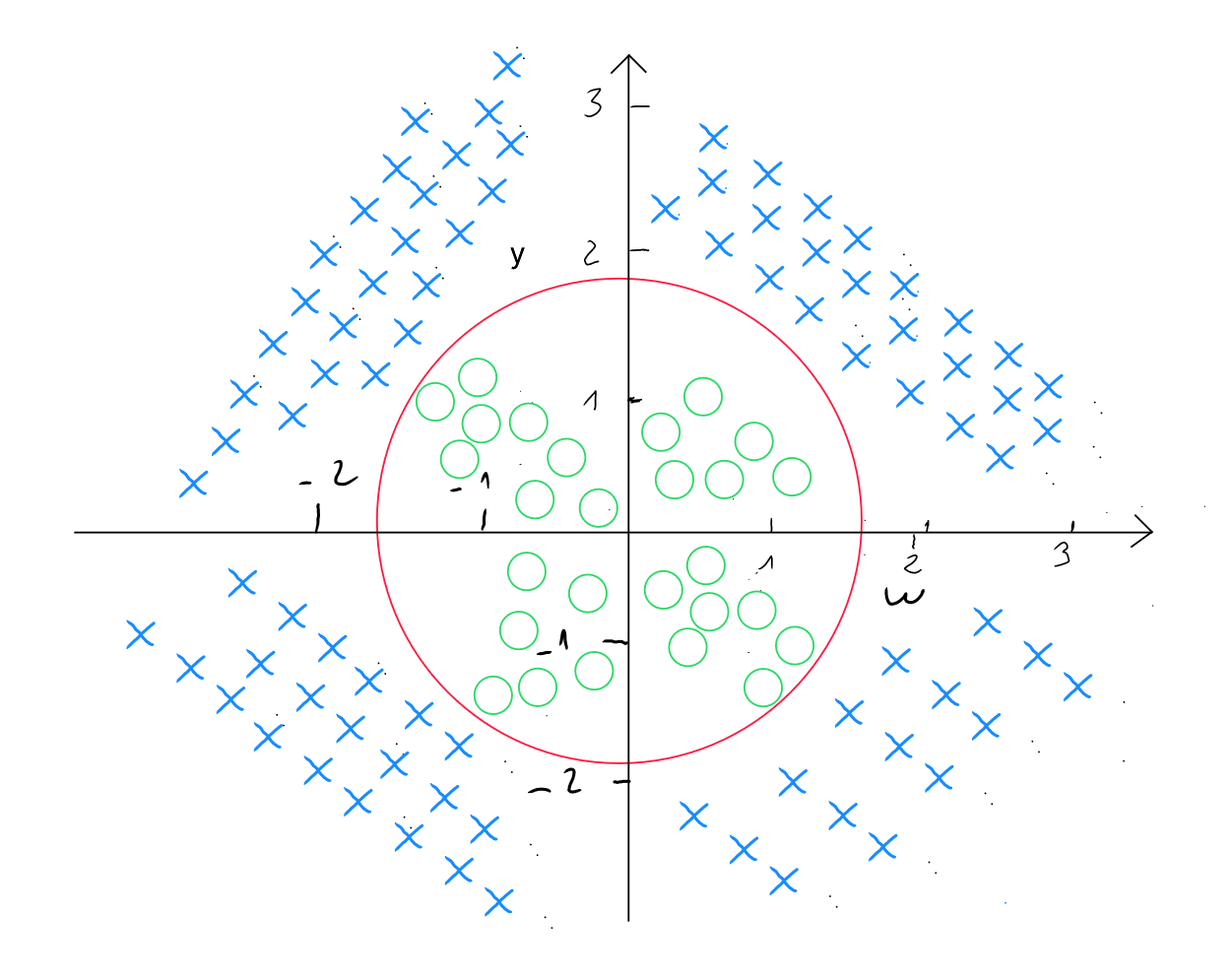
In the case of a non-linear threshold, we will use polynomial features by adapting the formula as follows ( for two predictors and ) :
or
Other degrees of polynomial forms are, of course, tested within the algorithm to find the best way to predict the information. For example, in the following cases :
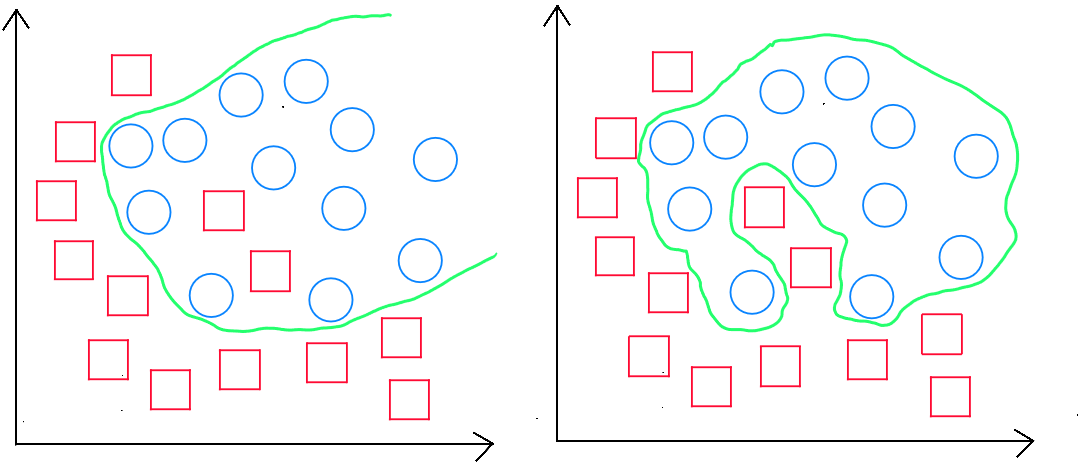
The equation would take the following form :
import numpy as np
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.model_selection import train_test_split
import math, copy
from sklearn.metrics import confusion_matrix
# Data split
data = pd.read_csv('data.csv')
# Variables split
x = data[['x_1', 'x_2', 'x_3', 'x_4', 'x_5', '...', 'x_n']].values
y = data['y'].values
# Generation of 3rd Degree Polynomial Terms
poly = PolynomialFeatures(degree=3)
x_poly = poly.fit_transform(x)
# Standardization of Polynomial Data
scaler_x = StandardScaler()
x_poly = scaler_x.fit_transform(x_poly)
# Splitting into Training and Test Sets
x_train, x_test, y_train, y_test = train_test_split(x_poly, y, test_size=0.4, random_state=42)
Cost Function
The shape of the cost function in linear regression is convex, which is optimal for the gradient descent algorithm, whose goal is - through iteration -to find the optimal values for and .
In linear regression, we use the following formula for the cost function :
The problem with logistic regression is that the shape of its cost function is non-convex, meaning that gradient descent can find several local optima that may not correspond to the true minimum and can get stuck in convergence.
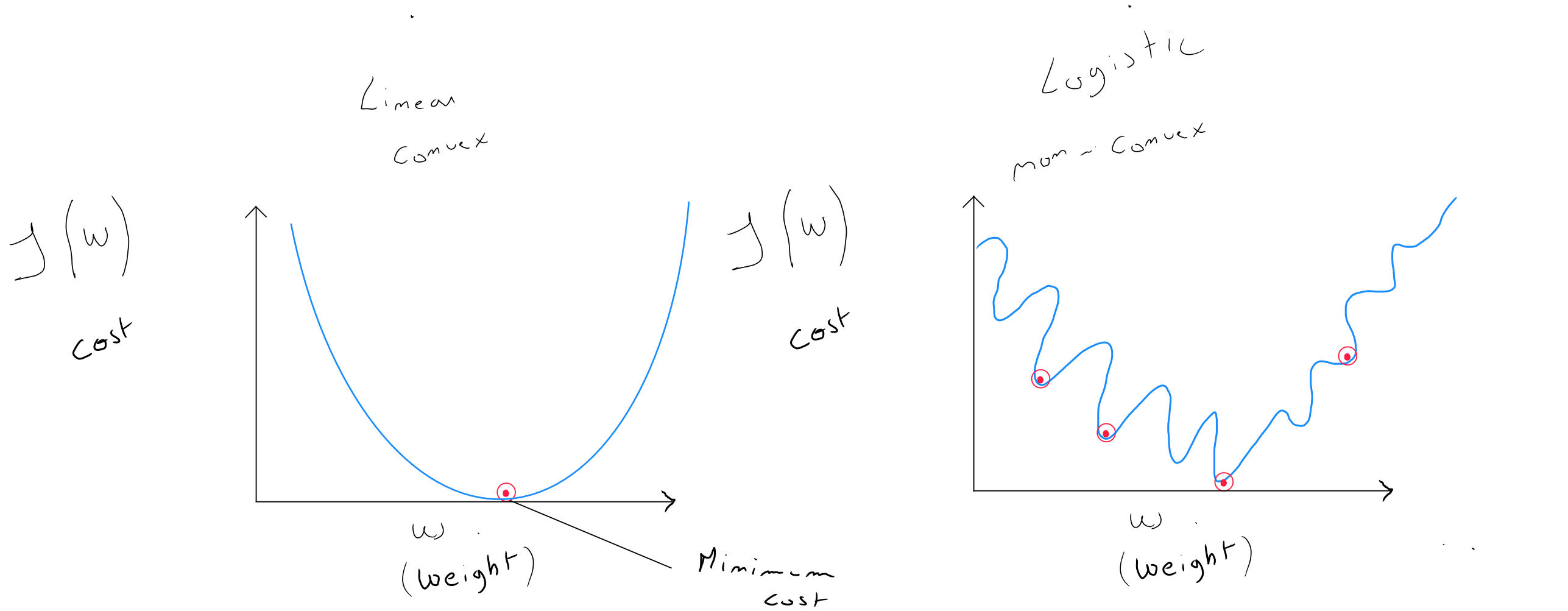
Logistic regression uses a « transformed » cost function from linear regression to make the cost function convex again, allowing it to converge towards a local optimum.
Loss Function
To adapt the cost function to logistic regression, let’s focus on the concept of loss, which can be isolated as part of the cost function , shown in blue in the formula below :
This loss function for all records can be rewritten as :
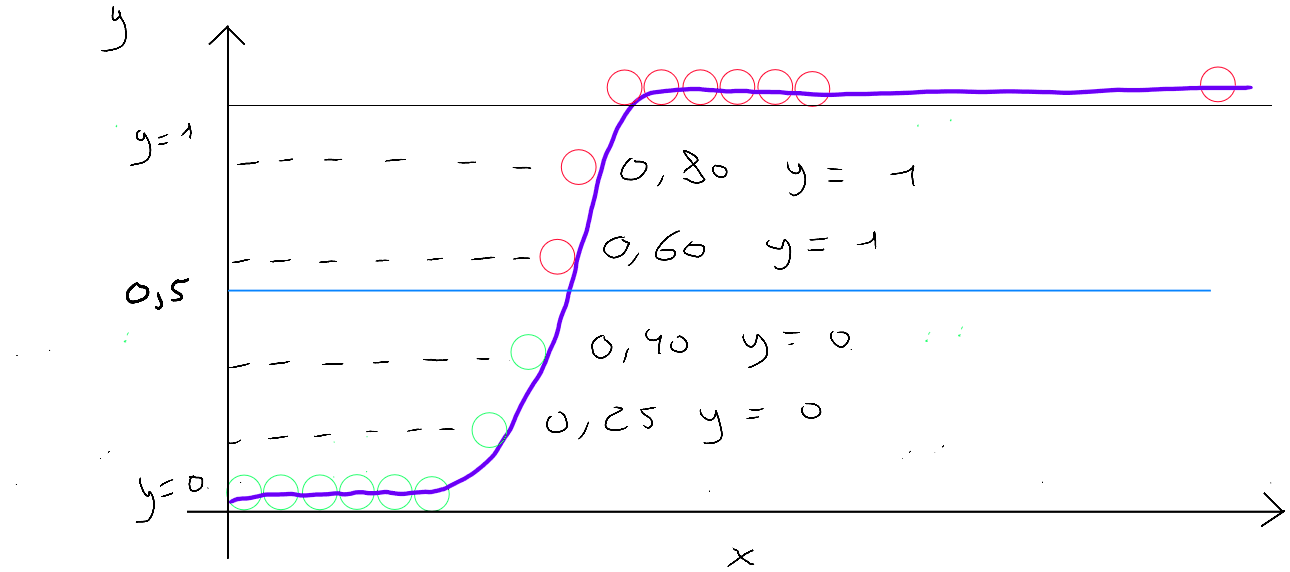
If we visualize by considering on the x-axis ( abscissa ), knowing that is the result of logistic regression ( a value between and ), it would resemble the green curve in the graph below ; and if we visualize , we would obtain the blue curve.
The intersection of the two curves on the x-axis corresponds to the value . The part of the function that concerns the result between and is the top left section, outlined in red.
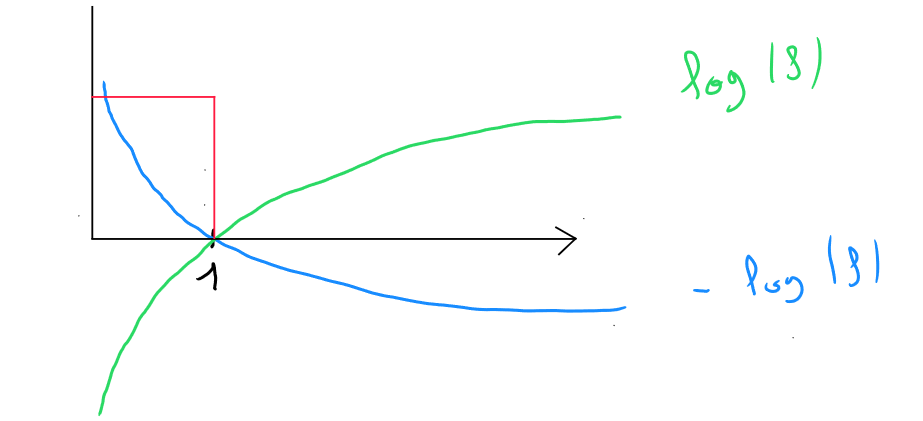
If we zoom in on this section and assume for the loss function and our model predicts :
- If the model predicts , the loss is ;
- If the model predicts , the loss is ;
- If the model predicts , the loss is ;
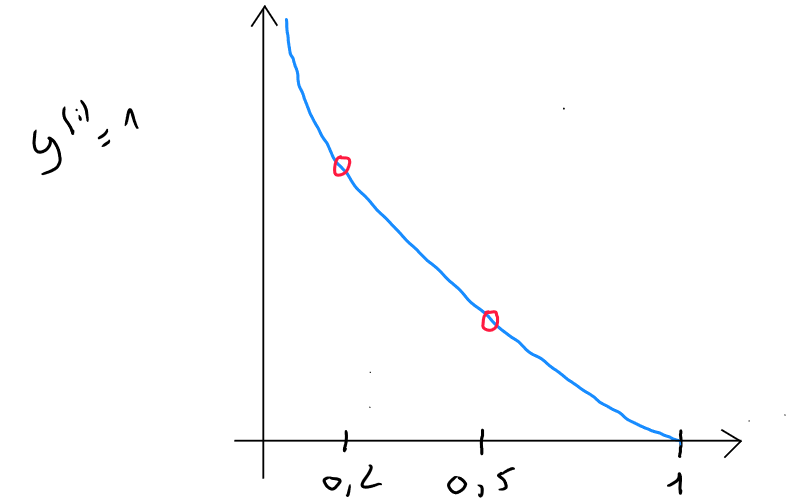
What we observe is that the algorithm will aim to reduce the loss and be as accurate as possible because predictions where but result in significant loss.
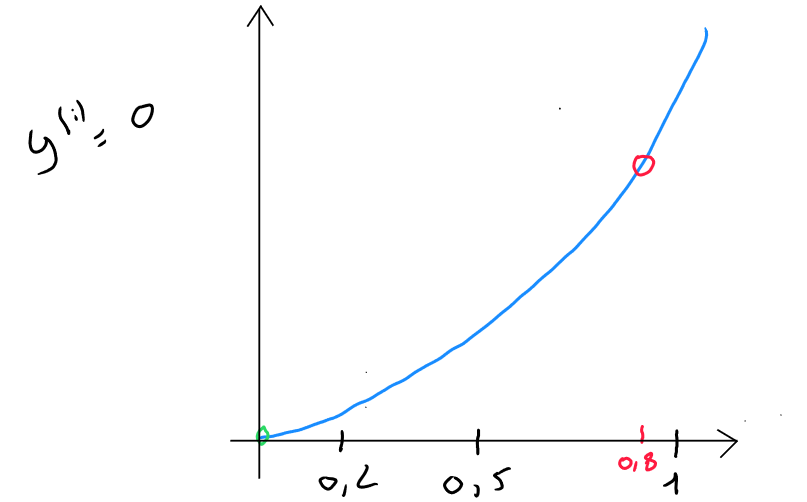
In the second case (), the algorithm will also aim to reduce the loss, and predictions where but result in significant loss.
Therefore, transforming the cost function :
Allows us to obtain a convex form and use gradient descent to find the local optimum.
Of course, the cost function applies to the entire dataset and will correspond to the sum of losses divided by :
The gradient descent algorithm will therefore try to find the parameters that minimize the cost function.
The loss function :
Can be simplified as follows :
It is simplified because it combines both cases ( or ) and automatically cancels one case if the other is assumed.
If and we substitute the values of into the formula :
The right-hand side is canceled because , and thus :
As a result, we get :
If and we substitute the values of into the formula:
The right-hand side is canceled because , and thus :
As a result, we get :
Let’s remember that the loss function is a part of the cost function (in blue) :
Corrected Cost Function (Convex)
Therefore, if we want to rewrite the entire cost function, small transformations will be applied to the operators, and we will obtain the following final formula :
This final cost function is derived from the principle of maximum likelihood estimation, which, in the context of logistic regression, allows for finding the parameters and in a convex form.
Corrected Cost Function (Convex) in Python
def compute_cost(X, y, w, b, lambda_= 1):
m, n = X.shape
cost = 0.
for i in range(m):
z = np.dot(X[i],w)+b
f_wb = sigmoid(z)
cost += -y[i]*np.log(f_wb) - (1-y[i])*np.log(1-f_wb)
total_cost = cost/m
#reg_cost = (lambda_ / (2 * m)) * np.sum(np.square(w))
#total_cost += reg_cost
return total_cost
Gradient Descent
Just like the gradient descent algorithm in linear regression, the goal of gradient descent in logistic regression is to find the model that minimizes the cost function . Defining the values of and will allow us to define the probability of belonging to class 1 ( where class 1 is generally the negative class ) for each new value of . .
The full cost function :
The implementation of the gradient to minimize the cost follows the same process as linear regression, namely :
For each iteration , it is important to define, temporarily, the new value of and the new value of and then replace them simultaneously.
- ;
- ;
- ;
- ;
This definition of the gradient descent steps is entirely similar to linear regression. That’s normal ; what changes is how the model is defined afterward :
- In linear regression, we have : ;
- In logistic regression, we apply , which gives : ;
Even though the gradient descent algorithm appears similar for both linear and logistic regression, they are indeed two different algorithms because of how they are applied in the model.
Odds Ratio
In statistics, the Odds Ratio is a measure that quantifies the strength of association between an explanatory variable ( predictor ) and the probability of occurrence of the event we want to predict (class 1, often representing the negative aspect, e.g. Spam 1, Non-Spam 0; Sick 1, Healthy 0).
The odds ratio evaluates the change in the probability of based on a one-unit increase in the explanatory variable.
Imagine we have 10 patients. Among them, 6 are sick and 4 have a fever. Among those with a fever, 3 are sick and 1 is not. The odds ratio will allow us to calculate the chance of having a fever when sick compared to not being sick and having a fever.
| Fever (p) | No Fever (q) | Total | |
|---|---|---|---|
| Sick | 3 (p) | 3 | 6 |
| Not Sick | 1 (q) | 3 | 4 |
| Total | 4 | 6 | 10 |
To calculate the odds ratio, we use the following formula (where is the proportion of sick patients with a fever, and is the proportion of non-sick patients with a fever) :
In our example: which equals ; which equals .
Thus :
The result indicates that sick patients are 3 times more likely to have a fever than non-sick patients.
This does not indicate the probability of having a fever if you're sick or being sick if you have a fever! It's simply the association between sickness and fever.
In logistic regression, the odds ratio is calculated from the coefficient found by the gradient descent method. The odds ratio for an explanatory variable is given by . For example, if the gradient descent identifies a value of for fever, the odds ratio is . This means the chances of being sick increase by when a patient has a fever compared to one who does not.
However, the odds ratio does not calculate probability but helps to better understand the multiplicative factor of chance that the event decreases or increases as the explanatory variable increases by one unit. It allows for easier comparison of the impact of different explanatory variables on the probability of the event.
The odds ratio helps in understanding the model’s functioning and results.
As a reminder, the probability will be calculated based on the value of a new record and the and values identified by the gradient descent.
Gradient Descent in Python:
def compute_gradient(X, y, w, b, lambda_=1):
m, n = X.shape
dj_dw = np.zeros(w.shape)
dj_db = 0.
for i in range(m):
f_wb_i = sigmoid(np.dot(X[i],w) + b)
err_i = f_wb_i - y[i]
for j in range(n):
dj_dw[j] = dj_dw[j] + err_i * X[i,j]
dj_db = dj_db + err_i
dj_dw = dj_dw/m
dj_db = dj_db/m
dj_dw += (lambda_ / m) * w
return dj_db, dj_dw
Launching Gradient Descent:
def gradient_descent(X, y, w_in, b_in, cost_function, gradient_function, alpha, num_iters, lambda_):
m = len(X)
J_history = []
w_history = []
for i in range(num_iters):
dj_db, dj_dw = gradient_function(X, y, w_in, b_in, lambda_)
w_in = w_in - alpha * dj_dw
b_in = b_in - alpha * dj_db
if i<100000:
J_history.append( cost_function(X, y, w_in, b_in, lambda_))
if i > 1 and abs(J_history[-1] - J_history[-2]) < 0.000001:
print(f"Early stopping at iteration {i} as cost change is less than 0.000001")
break
if i% math.ceil(num_iters / 10) == 0:
print(f"Iteration {i:4}: Cost {J_history[-1]} ",
f"dj_dw: {dj_dw}, dj_db: {dj_db} ",
f"w_in: {w_in}, b_in:{b_in}")
return w_in, b_in, J_history, w_history
np.random.seed(1)
initial_w = np.zeros(X_train.shape[1])
initial_b = 0
lambda_=0.01
iterations = 1000
alpha = 0.003
w,b, J_history,_ = gradient_descent(X_train ,y_train, initial_w, initial_b,
compute_cost, compute_gradient, alpha, iterations, lambda_)
Regularization
The principle of regularization in logistic regression is identical to what we find in linear regression.
That means, in the case of underfitting, the main option is to add more variables or additional records, and in overfitting, we also find basic options like increasing or reducing variables ( Variable Selection ) and increasing the number of records.
As with linear regression, reducing the number of variables is applied via the concept of feature engineering or through specific techniques.
If, for specific reasons, we as data scientists must keep all variables, we can also counter overfitting by applying regularization to logistic regression.
Recall that the concept of regularization involves reducing the impact of certain variables by assigning them a lower weight. Specifically, the idea is to make the learning algorithm reduce the values of parameters without forcing them to be set to . Regularization primarily applies to the values of , although regularization could also be applied to the parameter .
This penalty is applied by adding the following regularization term to the modified cost function of logistic regression :
Regularized Gradient Descent
- ;
- ;
- ;
- ;
Complete Python Code
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import math, copy
from sklearn.metrics import confusion_matrix
data = pd.read_csv('data.csv')
data
x = data[['x_1', 'x_2', 'x_3', 'x_4', 'x_5', '...', 'x_n']].values
y = data['y'].values
scaler_x = StandardScaler()
scaler_y = StandardScaler()
x = scaler_x.fit_transform(x)
y = scaler_y.fit_transform(y.reshape(-1, 1))
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.4, random_state=42)
#polynomial
"""
# Chargement des données
data = pd.read_csv('data.csv')
# Séparation des caractéristiques et de la cible
x = data[['x_1', 'x_2', 'x_3', 'x_4', 'x_5', '...', 'x_n']].values
y = data['y'].values
# Génération des termes polynomiaux de degré 3
poly = PolynomialFeatures(degree=3)
x_poly = poly.fit_transform(x)
# Standardisation des données polynomiales
scaler_x = StandardScaler()
x_poly = scaler_x.fit_transform(x_poly)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.4, random_state=42)
"""
# /Polynomial
def sigmoid(z):
g = 1/(1+np.exp(-z))
return g
def compute_cost(X, y, w, b, lambda_= 1):
m, n = X.shape
cost = 0.
for i in range(m):
z = np.dot(X[i],w)+b
f_wb = sigmoid(z)
cost += -y[i]*np.log(f_wb) - (1-y[i])*np.log(1-f_wb)
total_cost = cost/m
reg_cost = (lambda_ / (2 * m)) * np.sum(np.square(w))
total_cost += reg_cost
return total_cost
def compute_gradient(X, y, w, b, lambda_=1):
m, n = X.shape
dj_dw = np.zeros(w.shape)
dj_db = 0.
for i in range(m):
f_wb_i = sigmoid(np.dot(X[i],w) + b)
err_i = f_wb_i - y[i]
for j in range(n):
dj_dw[j] = dj_dw[j] + err_i * X[i,j]
dj_db = dj_db + err_i
dj_dw = dj_dw/m
dj_db = dj_db/m
dj_dw += (lambda_ / m) * w
return dj_db, dj_dw
def gradient_descent(X, y, w_in, b_in, cost_function, gradient_function, alpha, num_iters, lambda_):
m = len(X)
J_history = []
w_history = []
for i in range(num_iters):
dj_db, dj_dw = gradient_function(X, y, w_in, b_in, lambda_)
w_in = w_in - alpha * dj_dw
b_in = b_in - alpha * dj_db
if i<100000:
J_history.append( cost_function(X, y, w_in, b_in, lambda_))
if i > 1 and abs(J_history[-1] - J_history[-2]) < 0.000001:
print(f"Early stopping at iteration {i} as cost change is less than 0.000001")
break
if i% math.ceil(num_iters / 10) == 0:
print(f"Iteration {i:4}: Cost {J_history[-1]} ",
f"dj_dw: {dj_dw}, dj_db: {dj_db} ",
f"w_in: {w_in}, b_in:{b_in}")
return w_in, b_in, J_history, w_history
np.random.seed(1)
initial_w = np.zeros(X_train.shape[1])
initial_b = 0
lambda_=0.01
iterations = 1000
alpha = 0.003
w,b, J_history,_ = gradient_descent(X_train ,y_train, initial_w, initial_b,
compute_cost, compute_gradient, alpha, iterations, lambda_)
def predict(X, w, b):
m, n = X.shape
p = np.zeros(m)
for i in range(m):
z_wb = np.dot(X[i],w)
for j in range(n):
z_wb += 0
z_wb += b
f_wb = sigmoid(z_wb)
p[i] = 1 if f_wb>0.5 else 0
return p
p = predict(X_test, w, b)
confusion = confusion_matrix(y_test, p)
TP = confusion[1, 1] # True positive
FP = confusion[0, 1] # False positive
TN = confusion[0, 0] # True negative
FN = confusion[1, 0] # False negzative
print("Confusion matrix :")
print(confusion)
print("True positive (TP):", TP)
print("False positive (FP):", FP)
print("True negative (TN):", TN)
print("False negzative (FN):", FN)