Data Properties
Identifying data properties is fundamental in data science, whether the goal is to apply statistical techniques to create a learning model or to create visualizations for data storytelling.
Data refers to information that can be processed by a computer system and is conventionally available.
Structured Data
The most common type of data is structured data, which means it is stored in a tabular form. In a table, we find columns and rows. Different terms are used in the literature ; for instance, a column is often referred to in statistics as a variable - because its values vary - and as a field in business intelligence. The term « attribute » is also used.
A row - a record - corresponds to a value of a column in a table. A record can also be called an individual or object.
| OrderID | CustomerID | ProductID | Date | Amount |
|---|---|---|---|---|
| 16208 | 255 | 6425 | 08/08/2024 | 45.28 |
| 16208 | 255 | 3498 | 08/08/2024 | 55.64 |
| 16208 | 255 | 1528 | 08/08/2024 | 9.99 |
| 16208 | 255 | 0056 | 14/08/2024 | 13.50 |
| 16209 | 094 | 1134 | 14/08/2024 | 32.99 |
| 16209 | 094 | 4657 | 14/08/2024 | 24.25 |
| 16209 | 094 | 2298 | 14/08/2024 | 8.45 |
Semi-Structured Data
The second most common type of data is semi-structured data. This data is not represented in tabular form but has metadata that allows its characteristics to be grouped. Examples include XML, HTML, JSON, and CSV formats. Semi-structured data does not depend on a rigid database structure and, as a result, offers greater flexibility in its evolution.
Example of semi-structured data: <?xml version="1.0"?>
<Order id="16208">
<CustomerID>255</CustomerID>
<ProductID>0056</ProductID>
<Date>14/08/2024</Date>
<Amount>13.50</Amount>
</Order>
<Order id="16209">
<CustomerID>094</CustomerID>
<ProductID>1134</ProductID>
<Date>14/08/2024</Date>
<Amount>32.99</Amount>
</Order>
Unstructured Data
The third type of data is unstructured data. This data is stored in its original format, independent of any computer system. Examples include images, videos, audio, and text.
Structured, semi-structured, and unstructured data can be used for developing learning models, whereas business intelligence typically only accepts structured or semi-structured data for creating visualizations.
Nature of Variables
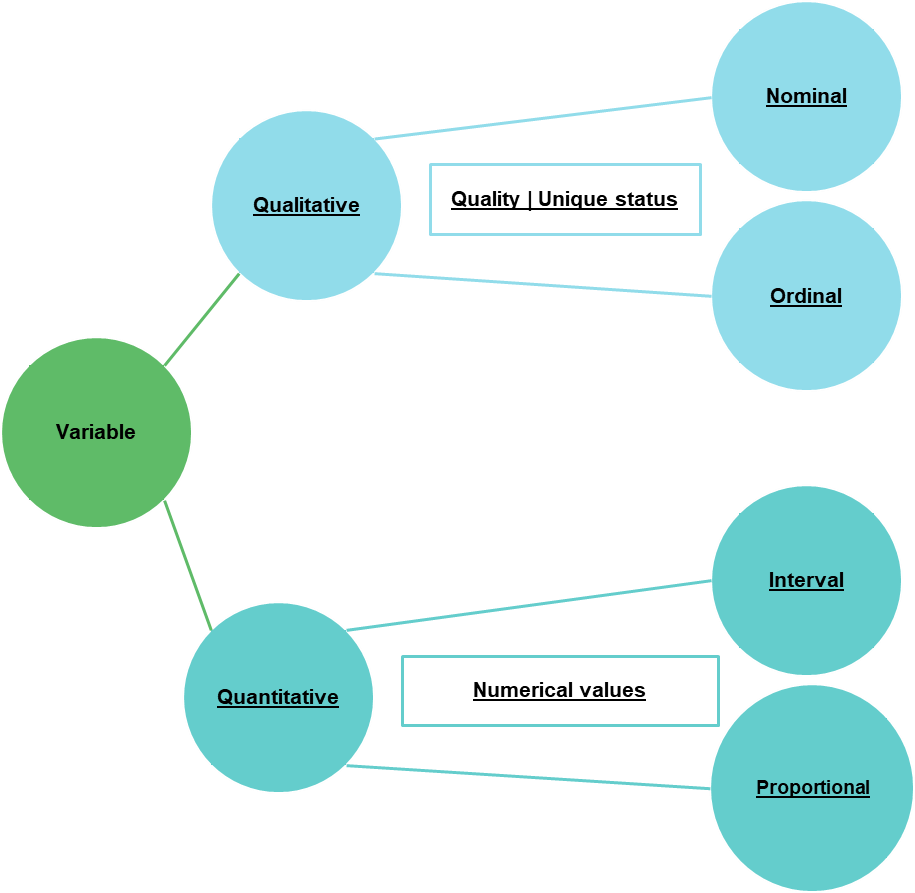
A variable - a column in a table, attribute, or field - contains two types of data : qualitative data and quantitative data.
Qualitative data expresses a quality, meaning a unique status, and is discrete in nature : the values can be listed and repeated across multiple records. For example, eye color values can be listed ( blue, green, brown, hazel, amber ), and the same value could be repeated for multiple individuals.
A qualitative variable is divided into two categories :
- Ordinal qualitative variable : the values can be organized according to a certain hierarchy. Example : Large, Medium, Small - we can define that large is in a higher order of magnitude than medium, which is itself in a higher order of magnitude than small -.
- Nominal qualitative variable : the values cannot be organized according to a certain hierarchy. Example : blue, green, yellow. We cannot define an order determining that blue is better than green or yellow.
Quantitative data contains numerical values that can be measured or aggregated ( quantified ). Examples include height, weight, income, age, temperature, etc.
A quantitative variable is also divided into two subcategories :
- Proportional quantitative variable : the differences between values can be characterized by equal proportions, so there is a mathematical and constant relationship. Example : a person who weighs 90 kg is twice as heavy as someone who weighs 45 kg. A rent of 1125 euros is 1.5 times higher than a rent of 750 euros.
- Interval quantitative variable : the intervals between values are not constant. Example : temperature measurements - 15/12/2024 13:45:34 7.2°C; 15/12/2024 13:46:15 7.1°C; 15/12/2024 13:52:55 7.4°C -.
Dates and times/minutes/ seconds
A date or a date/time ( timestamp ) is considered numeric in computing - a quantitative variable -. Although formatted as DD/MM/YYYY hh:mm:ss, the computer interprets it as a number : the number of days ( and seconds / minutes ) that have passed since a reference date.
This reference date is not the same across all languages, but the most common is 31/12/1899. Thus, the date 22/12/2024 at 06:00:00 corresponds in computing to 45648.25, which is 45648 days after 31/12/1899, equating to 22/12/2024. Regarding the timestamp, simply multiply the decimal part by 24 to get the number of hours : 24 * 0.25 = 6h.
If residual values remain after defining the hour, these represent minutes and seconds. Multiply the first residual value by 60 to obtain minutes, and if residual values persist, multiply by 60 to get seconds.
For example, if we had 0.249877, it would be 5:59 and 49 seconds because 0.249877 * 24 = 5.997048 ( 5h ); 0.997048 * 60 = 59, and finally 0.82288 * 60 = 49.Applications
Supervised or Unsupervised Model
The distinction between qualitative and quantitative is crucial for any data analysis. For example, if the project's goal is prediction, meaning the use of supervised statistical techniques to create a learning model, as discussed in the chapter - learning concepts - there are two prediction options : either estimation ( the target variable - predicted - is a quantitative variable ) or classification ( the target variable - predicted - is a qualitative variable ).
Depending on the techniques, it is also essential to note that certain variables used as predictors may be quantitative only, qualitative only, or both quantitative and qualitative. As data scientists, we may need to transform quantitative variables into qualitative variables ( discretize ) or transform a qualitative variable into a quantitative variable ( numerize / binarise ).
If the project's goal is to use unsupervised statistical techniques to create a model that highlights hidden trends, the same principle can apply depending on the technique.
B.I. Measures vs. Dimensions
Just as the concept of qualitative or quantitative variables is important in defining measures and dimensions in business intelligence.
In a business intelligence model, a measure is an aggregation formula applied to the values of a column - like SUM, MIN, MAX, or AVERAGE - to produce a value result at the time of the query, that is, during the filter selection by the dashboard user. A measure expression can be basic ( basic aggregation ) but can also apply a set of rules that can replace table relationships or data filtering context.
A dimension is a column in a table - non-aggregated - that allows applying a filter on the measure or segmenting it. A dimension is in most cases non-numerical data - a qualitative variable - that does NOT allow calculations, such as Name, Day, Country, etc. Note the exception to the rule : the Count aggregation, which allows a measure to be made based on a dimension, and thus a qualitative variable Count(distinct ProductName).
A measure answers the question : what is the key performance indicator ( KPI ) we want to analyze ; the dimension answers the question : by what do we want to analyze this key performance indicator. Example : the key performance indicator ( KPI ) is the sales amount - sum(sales) - and the dimension is « Country ». This allows us to get a chart - such as a bar chart - where if we had no dimensions, we would have a single bar ( total sales ), and by applying dimensions, we get as many bars as there are values in the qualitative variable country and thus the total sales by country.
To better understand the difference between measures and dimensions in a chart, you can find the dedicated page here: measures & dimensions in business intelligence