Propriétés des données
L'identification des propriétés des données est fondamental en data sciences. Que ce soit dans un objectif d'application de techniques statistiques en vue de créer un modèle d'apprentissage ou pour la création de visualisations dans un objectif de Data Storytelling.
Une donnée est une information exploitable par un système informatique et disponibles de manière conventionnelle.
Données stucturées
Les données les plus courantes sont de type structuré, ce qui signifie qu'elle sont stockées sous une forme tabulaire. Dans une table, nous retrouvons des colonnes et des lignes. Nous retrouvons dans la littérature différentes dénominations ; ainsi une colonne est souvent nommée dans le domaine de la statistique variable - car ses valeurs varient - et champ en informatique décisionnelle. On retrouve également l'appellation attribut.
Une ligne - un enregistrement - correspond à une valeur d'une colonne d'une table. Un enregistrement peut également être nommé individu ou objet.
| OrderID | CustomerID | ProductID | Date | Montant |
|---|---|---|---|---|
| 16208 | 255 | 6425 | 08/08/2024 | 45.28 |
| 16208 | 255 | 3498 | 08/08/2024 | 55.64 |
| 16208 | 255 | 1528 | 08/08/2024 | 9.99 |
| 16208 | 255 | 0056 | 14/08/2024 | 13.50 |
| 16209 | 094 | 1134 | 14/08/2024 | 32.99 |
| 16209 | 094 | 4657 | 14/08/2024 | 24.25 |
| 16209 | 094 | 2298 | 14/08/2024 | 8.45 |
Données semi-structurées
Le second type de données le plus courant est de type semi-structuré. Ce sont des données qui ne sont pas représentées sous forme tabulaire mais qui disposent de métadonnées permettant de regrouper leur caractéristiques. Nous pouvons citer comme exemples les formats XML, HTML, JSON, CSV, etc. Les données semi-structurées ne dépendent pas d'une structure de base de données rigide et disposent en conséquence d'une plus grande flexibilité dans leur évolution.
Exemple de données semi-structurées : <?xml version="1.0"?>
<Order id="16208">
<CustomerID>255</CustomerID>
<ProductID>0056</ProductID>
<Date>14/08/2024</Date>
<Montant>13.50</Montant>
</Order>
<Order id="16209">
<CustomerID>094</CustomerID>
<ProductID>1134</ProductID>
<Date>14/08/2024</Date>
<Montant>32.99</Montant>
</Order>
Données non-structurées
Le troisième type de données est de type non-structuré. Ce sont des données stockées dans leur format d'origine, indépendamment de tout système informatique. Nous retrouvons comme exemple des images, des vidéos, des audio, des textes.
Les données structurées, semi-structurées et non structurées sont exploitables pour la réalisation de modèles d'apprentissage alors que l'informatique décisionnelle n'accepte que des données de type structuré ou semi-strucuré qui pourront servir à la réalisation de visuels.
Nature des variables
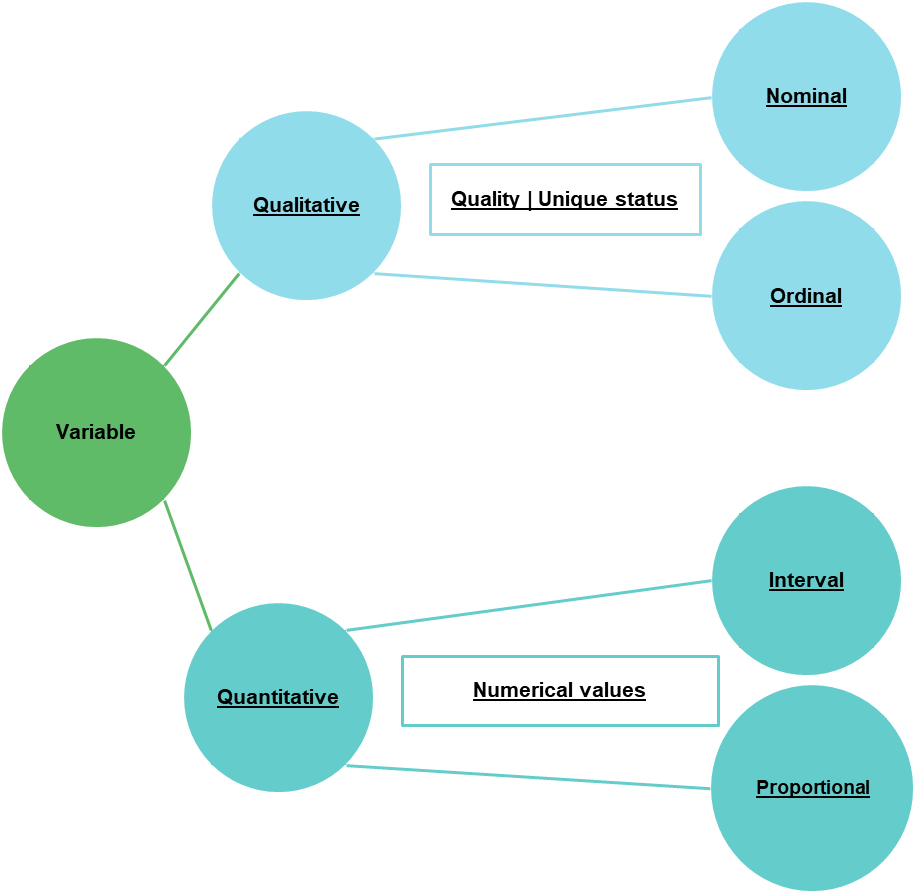
Une variable - une colonne d'une table, attribut ou champ -, contient deux types de données : les données qualitatives et les données quantitatives.
Une données qualitative exprime une qualité, c'est à dire un statut unique et est de nature discrète : les valeurs peuvent être listées et répétées pour plusieurs enregistrements. Prenons l'exemple de la couleur des yeux. Les valeurs peuvent être listées (bleu, vert, marron, noisette, ambre ), et la même valeur pourrait être répétée pour plusieurs individus.
Une variable qualitative est dissociée en deux catégories :
- Variable qualitative ordinale : les valeurs peuvent être organisées selon une certaine hiérarchie. Exemple : Grand, Moyen, Petit - nous pouvons définir que grand est dans un ordre de grandeur plus important que moyen qui lui-même est considéré dans un ordre de grandeur plus important que petit.
- Variable qualitative nominale : les valeurs ne peuvent pas être organisées selon une certaine hiérarchie. Exemple : bleu, vert, jaune. Nous ne pouvons pas définir un ordre déterminant que bleu est meilleur ou que vert ou que jaune.
Une données quantitative contient des valeurs numériques - qui peuvent être mesurées ou agrégées ( que l'on peut quantifier ). Nous retrouvons comme exemple la taille, le poids, le revenu, l'âge, la température,...
Une variable quantitative est également dissociée en deux sous-catégories :
- Variable quantitative proportionnelle : les différences entre les valeurs peuvent être caractérisées par des proportions égales de sorte qu'il existe une relation mathématique et constante. Exemple : Une personne qui pèse 90kg est deux fois plus lourde qu’une personne qui pèse 45 kg. Un loyer de 1125 euros est 1,5 fois plus élevé qu’un loyer de 750 €.
- Variable quantitative intervalle : les intervalles entre les valeurs ne sont pas constantes. Exemple : mesure de la température – 15/12/2024 13:45:34 7,2 C° ; 15/12/2024 13:46:15 7,1 C° ; 15/12/2024 13:52:55 7,4 C°.
dates et heures/minutes/secondes
Une date ou une date/heure ( timestamp ) est considérée comme numérique en informatique - variable quantitative. Bien qu'elle soit formatée DD/MM/YYYY hh:mm:ss, l'ordinateur interprète un chiffre : le nombre de jours ( et de secondes / minutes ) qui se sont écoulés depuis une date référentielle.
Cette date référentielle n'est pas identique d'un langage à l'autre mais nous retrouvons majoritairement le 31/12/1899. Ainsi, la date du 22/12/2024 à 06:00:00 correspond de manière informatique à 45648.25 soit 45648 jours après le 31/12/1899 qui correspond au 22/12/2024 et concernant le timestamp, il suffit de multiplier le nombre décimal par 24 pour obtenir le nombre d'heure : 24 * 0.25 = 6h.
Si vous obtenez des valeurs résiduelles suite à la définition de l'heure, il s''agit alors des minutes et secondes. Vous multipliez la première valeur résiduelle par 60 pour obtenir les minutes et si vous avez encore des valeurs résiduelles, vous multipliez par 60 pour obtenir les secondes.
Par exemple, si nous avions eu 0.249877, il serait 5h59 et 49 secondes car 0.249877 * 24 = 5.997048 ( 5 h ) ; 0.997048 * 60 = 59 et enfin 0.82288 * 60 = 49. 82288 * 60 = 49.Applications
Modèle supervisé ou non-supervisé
La distinction entre qualitatif et quantitatif est primordial pour toute exploitation des données. Par exemple si l'objectif du projet est de faire de la prédiction, c'est à dire d'utiliser des techniques statistiques supervisées afin de créer un modèle d'apprentissage ; comme nous l'abordons dans le chapitre - Notions d'apprentissage -, il existe deux options de prédiction : soit une estimation ( la variable cible - prédite - est une variable quantitative ) ; soit un classement ( la variable cible - prédite - est une variable qualitative ).
Selon les techniques, il est également essentiel de rappeler que certaines variables utilisées comme prédicteur peuvent être soit quantitative uniquement, soit qualitative uniquement soit quantitative ou qualitative. En tant que data scientist, nous serons donc peut être amené à transformer des variables quantitatives en variables qualitatives ( discrétiser ) ou transformer une variable qualitative en variable quantitative ( numériser / binariser ).
Si l'objectif du projet est d'utiliser des techniques statistiques non supervisées pour créer un modèle mettant en avant des tendances cachées, le même principe peut s'appliquer selon la technique.
B.I. Mesures vs dimensions
De même que la notion de variable qualitative ou quantitative est importante en ce qui concerna la définition des mesures et dimensions en informatique décisionnelle.
Dans un modèle en informatique décisionnelle, une mesure est une formule d’agrégation appliquée sur les valeurs d'une colonne - comme SUM, MIN, MAX ou AVERAGE - pour produire un résultat de valeur au moment de la requête, c'est à dire lors de la sélection de filtre par l'utilisateur du Dashboard. Une expression de mesure peut être basique ( agrégation de base ) mais également appliquer un ensemble de règles pouvant remplacer les relations de tables ou contexte de filtrage des données.
Une dimension est une colonne d’une table - non agrégée - qui permet d’appliquer un filtre sur la mesure ou de segmenter cette dernière. Une dimension est dans la plupart des cas une donnée non-numérique - variable qualitative - qui ne permet PAS les calculs tels que Nom, Jour, Pays, etc. Attention à l’exception de la règle : l'agrégation Count qui permet de réaliser une mesure sur base d’une dimension et donc une variable de type qualitative Count(distinct ProductName).
Un mesure répond à la question : quel est l'indicateur clé de performance ( KPI ) que je souhaite analyser ; la dimension répond à la question : par quoi je veux analyser cet indicateur clé de performance. Exemple : l'indicateur clé de performance (KPI) est le montant des ventes - sum(sales) - et la dimension est "Pays". Cela nous permettra d'obtenir un graphique - par exemple un bar chart - où si nous n'avions pas de dimensions, nous aurions une seule barre ( total des ventes ) et en appliquant les dimensions, j'obtiens autant de barres qu'il n'y a de valeur dans la variable qualitative pays et donc le total des ventes par pays.
Pour mieux comprendre la différence entre les mesures et dimensions dans un graphique, vous retrouverez ici la page dédiée aux mesures & dimensions en informatique décisionnelle