Data visualization
La visualisation de données tire ses fondements sur la théorie de gestalt selon laquelle l'esprit humain, face à la complexité, structure spontanément l'information visuelle pour en simplifier l'interprétation.
La vision humaine représente 80 % des informations qui sont transmises au cerveau. Le principe de la visualisation de données est donc de fournir une information de manière adaptée et interpellante d'un point de vue cognitif humain.
« a plus grande valeur d'une image, c’est quand elle nous oblige à constater ce que nous ne nous attendions jamais à voir. » (John Tukey - l'un des plus importants statisticiens américains du XXᵉ siècle).
La data visualisation permet de transformer de grandes quantités de données brutes en informations claires et accessibles, par l'utilisation de graphiques et autres représentations visuelles. Elle facilite la compréhension, l'analyse et la communication des données au sein d'une entreprise ou d'une organisation.
Mesures & Dimensions
En data visualization, on ne parle plus de variables quantitatives ou variables qualitatives [cf Propriétés des données], mais on parle de mesures - indicateurs clés de performance - (= qu'est-ce que je souhaite analyser) et dimensions (= par quoi je souhaite analyser cette mesure).
Par exemple, prenons comme indicateur clé de performance (KPI) le montant des ventes. Une mesure est une agrégation (min, max,sum, avg, ..) appliquée sur une colonne d'une table et il s'agit la plupart du temps d'une agrégation sur une colonne numérique et donc quantitative. Pour le montant des ventes, nous avons une table qui comprends pour chaque fruit un montant et nous agrégons cette colonne en appliquant une somme Sum[Amount].
| Fruits | Amount |
|---|---|
| Apple | 40 |
| Blueberry | 100 |
| Cherry | 30 |
| Orange | 55 |
Si nous décidons de représenter visuellement le KPI « montant des ventes » sum[Amount] dans un graphique en barres - donc uniquement une mesure sans dimension -, nous obtenons une seule barre car Il s'agit de la forme la plus agrégée des données ; uniquement la mesure soit .
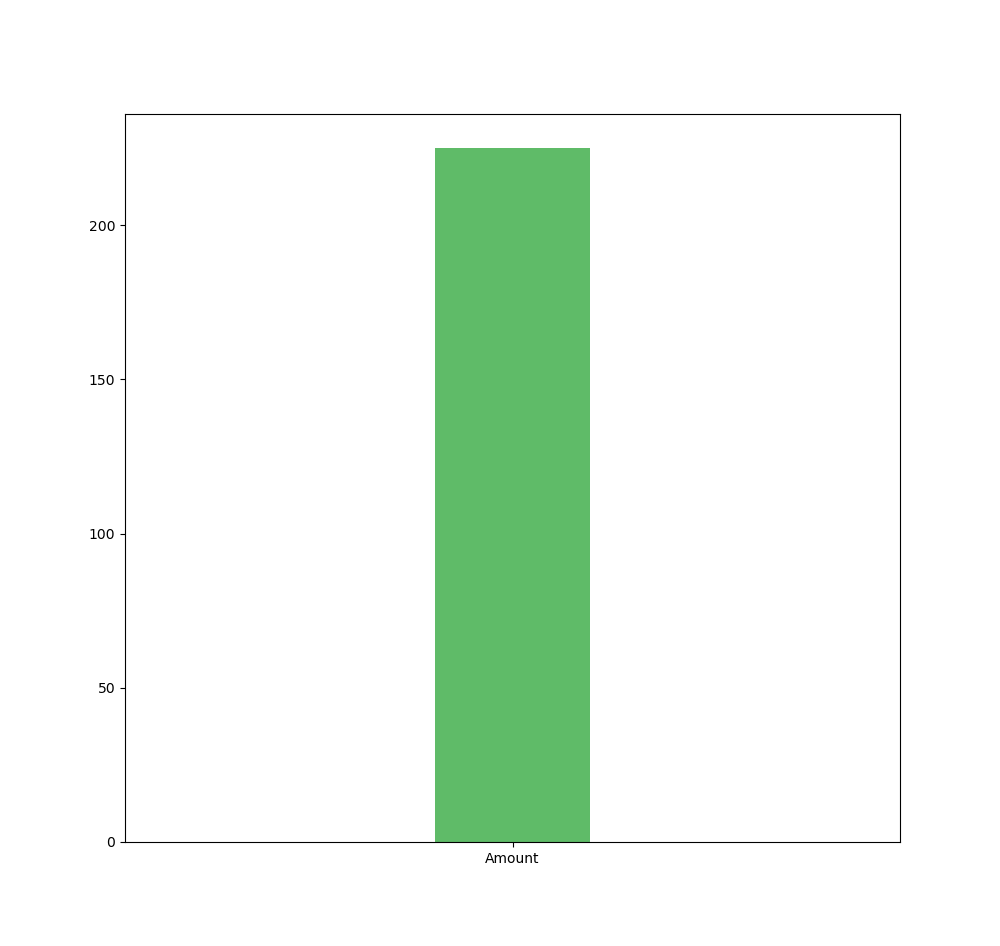
Si par contre, nous ajoutons la dimension « fruits » : nous voulons analyser les ventes par fruits ( cela pourrait être par magasin, par client,... ) ; nous obtenons une barre par valeur de dimension. La mesure qui était dans sa forme la plus agrégée est maintenant désagrégée par valeurs de la dimension utilisée ; dans ce cas : les fruits.
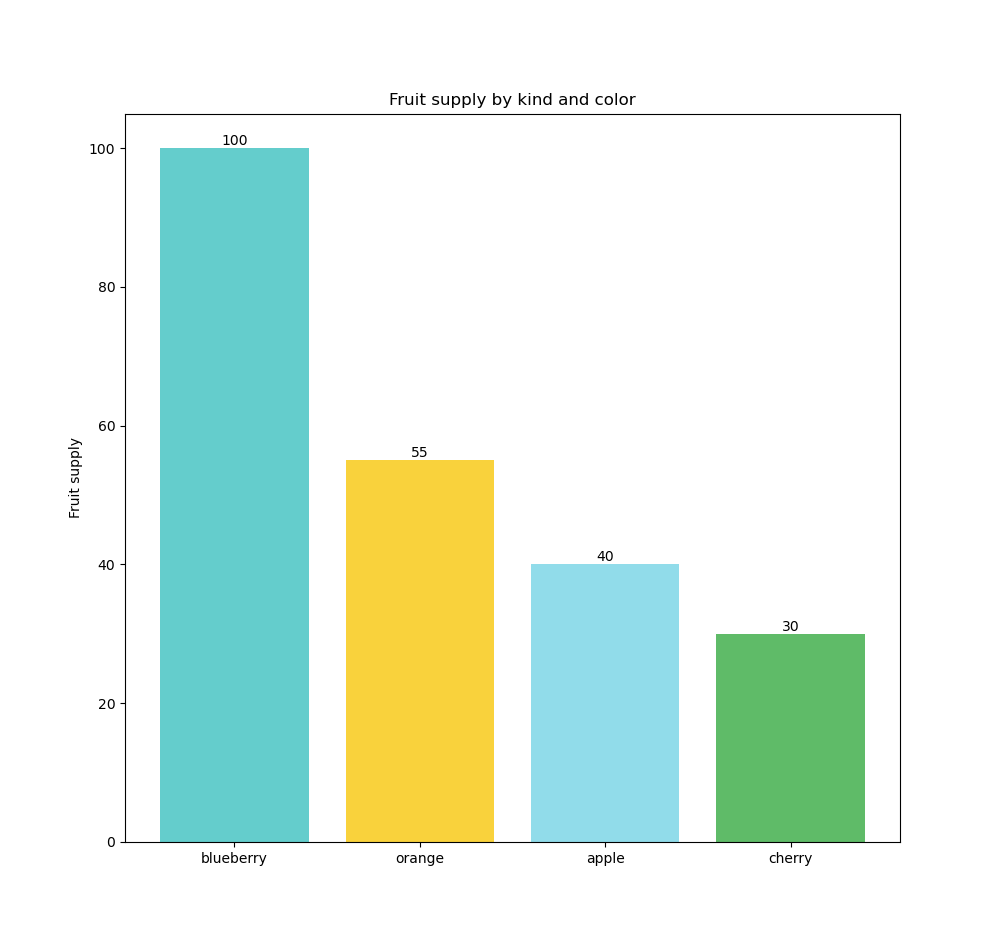
Dans le premier cas, en ajoutant la mesure, on obtient la forme la plus agrégée ( = qu'est-ce que nous voulons analyser | réponse : le montant des ventes ) et dans le second cas, en ajoutant la dimension, on désagrège ( on découpe ) la mesure par autant de valeurs qu'il existe dans la dimension, soit quatre barres car il y a quatre fruits.
Une mesure peut également s'appliquer à une variable qualitative. Par exemple : fruits - si nous voulons savoir combien nous avons de fruits, nous appliquons l'agrégation « count » sur fruits - Count[Fruits] ( qui est une variable qualitative nominale ) et nous obtenons . L'agrégation count est souvent utilisée pour créer des mesures à partir de variables qualitatives.
Les catégories de visuels
La question la plus complexe en data visualisation concerne le choix du graphique. Quel graphique pour quelle mesure et ou dimension ? Il est important tout d'abord de spécifier que selon la visualisation, il est possible d'ajouter plusieurs dimensions et/ou plusieurs mesures.
Par exemple, un bar chart - le graphique le plus populaire car le plus efficace pour le cerveau humain - permet plusieurs configurations : (1) horizontal vs vertical ; (2) 1 mesure et 2 dimensions groupées ; (3) 1 mesure et 2 dimensions Stacked ; (4) 1 dimension plusieurs mesures ; (5) Stacked ou non Stacked s'il y a plusieurs mesures ou plusieurs dimensions ; (6) Grouped, Stacked normal ou stacked 100 % ; etc.
La meilleure recommandation lorsqu'on démarre en data visualisation, c'est de garder à l'esprit la simplicité. L'utilisation de visualisations complexes peut être appliquée uniquement à partir du moment où il existe une certaine maturité data dans l'organisation. C'est à dire que lorsque les utilisateurs finaux sont habitués et formés. Dans le cas contraire ou lorsqu'un projet est initié, il est recommandé de se focaliser sur les visalusations les plus connues (et efficaces selon les situations), à savoir : le bar chart, le line chart, le combo chart, le pie chart, le scatter plot et les tables (straight & pivot).
Il existe quatre type de présentations de base :
Les visualisations de comparaison
Les visusalisations de comparaison répondent aux questions de base lorsque l'on démarre avec la data visualisation, telles que « Quel client représente les meilleures ventes ? » ou encore « quel produit est le plus cher à l'achat » ou « quelle est l'évolution du chiffre d'affaire cette année par rapport à l'année passe ? ». Il s'agit de comparer l'amplitude des valeurs les unes par rapport aux autres pour pouvoir identifier le plus rapidement possible, la plus basse et la plus haute valeur ou pour comparer les valeurs actuelles avec les valeurs anciennes.
Bar chart 1 mesure & 1 dimension ; Line Chart 1 mesure et 1 dimension
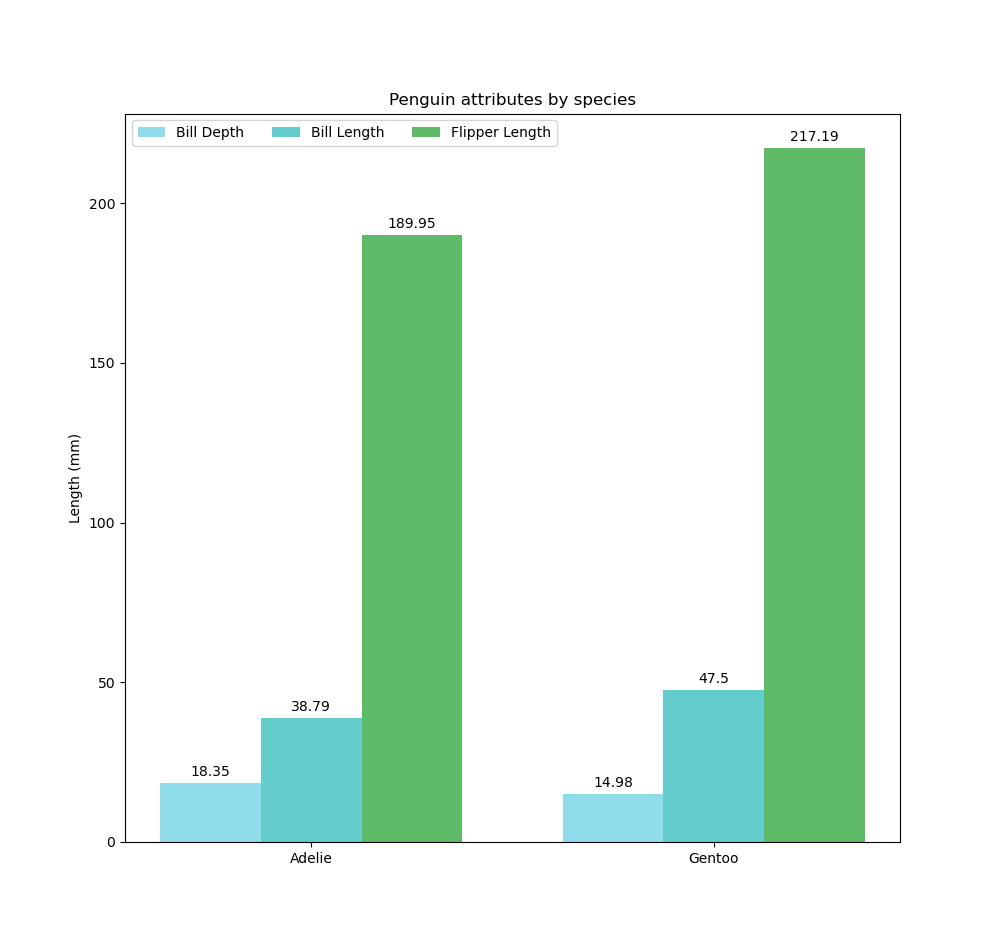
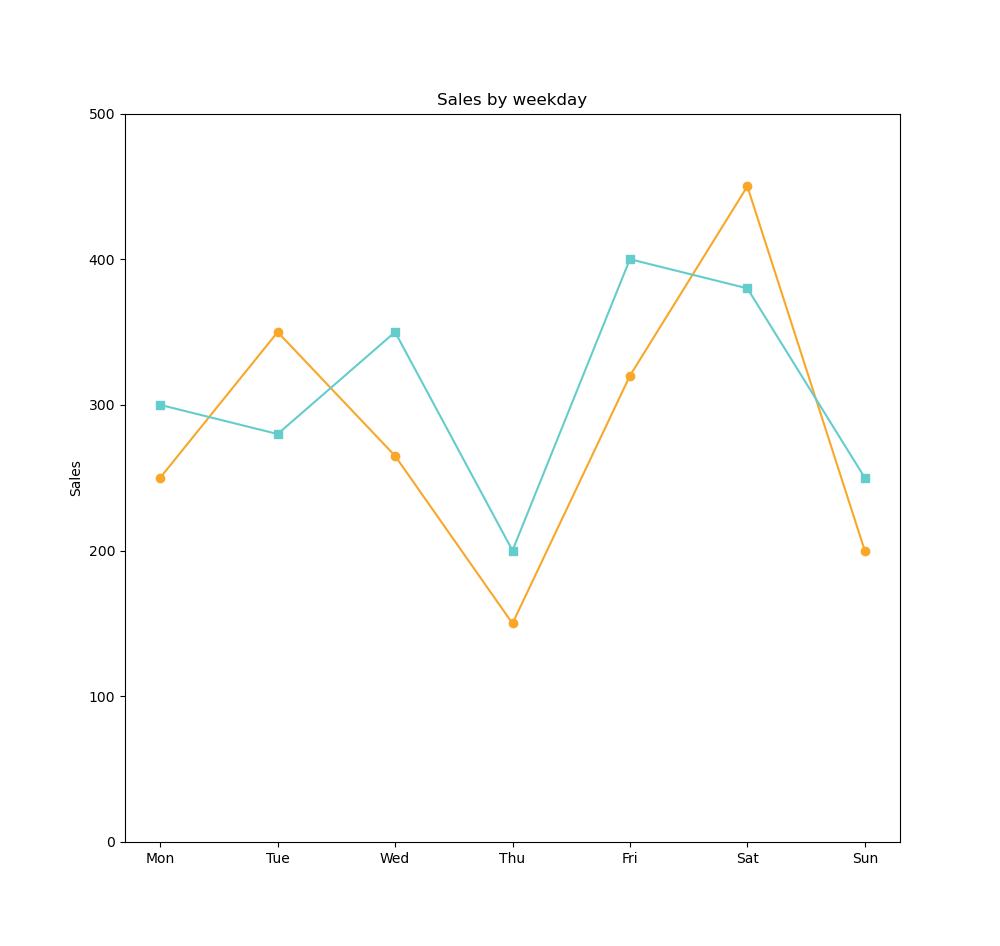
Les visualisations de relation
Les visualisations de relation sont utilisées pour pouvoir identifier des corrélations, des valeurs considérées comme « outliers » ou également visualiser des clusters, c'est à dire des groupes de points dont la particularité est que les points dans un groupe sont proches les uns des autres mais les groupes sont espacés les uns des autres. Nous retrouvons principalement dans cette catégorie le scatter plot ou nuage à points.
Graphique de gauche : Nuage à points 3 mesures ( axe Y, axe X + taille des bulles ) & 2 dimensions ( bulles & couleur des bulles ) : identficiation de corrélations, outliers ou clusters ; Graphique de droite : Sankey chart qui met en avant les relations de flux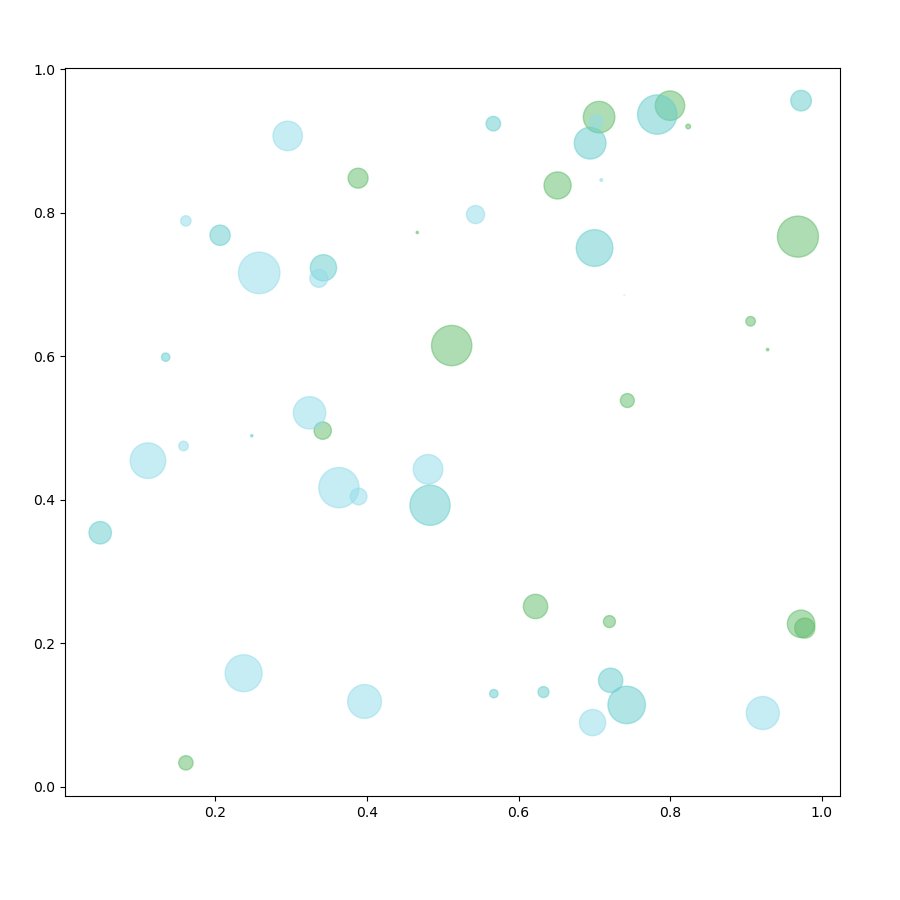

Les visualisations de composition
Les visualisations de composition permettent de comparer une valeur par rapport à un tout et intègrent une notion de part. Les valeurs sont souvent exprimées par défaut en pourcentage. Ils sont très utiles pour résumer un ensemble de données nominales ou présenter les différentes valeurs d’une variable données ( répartition en pourcentage ). Ils répondent à des questions de type : « Quelle est la part de ventes par région »?.
Pie chart & Donut Chart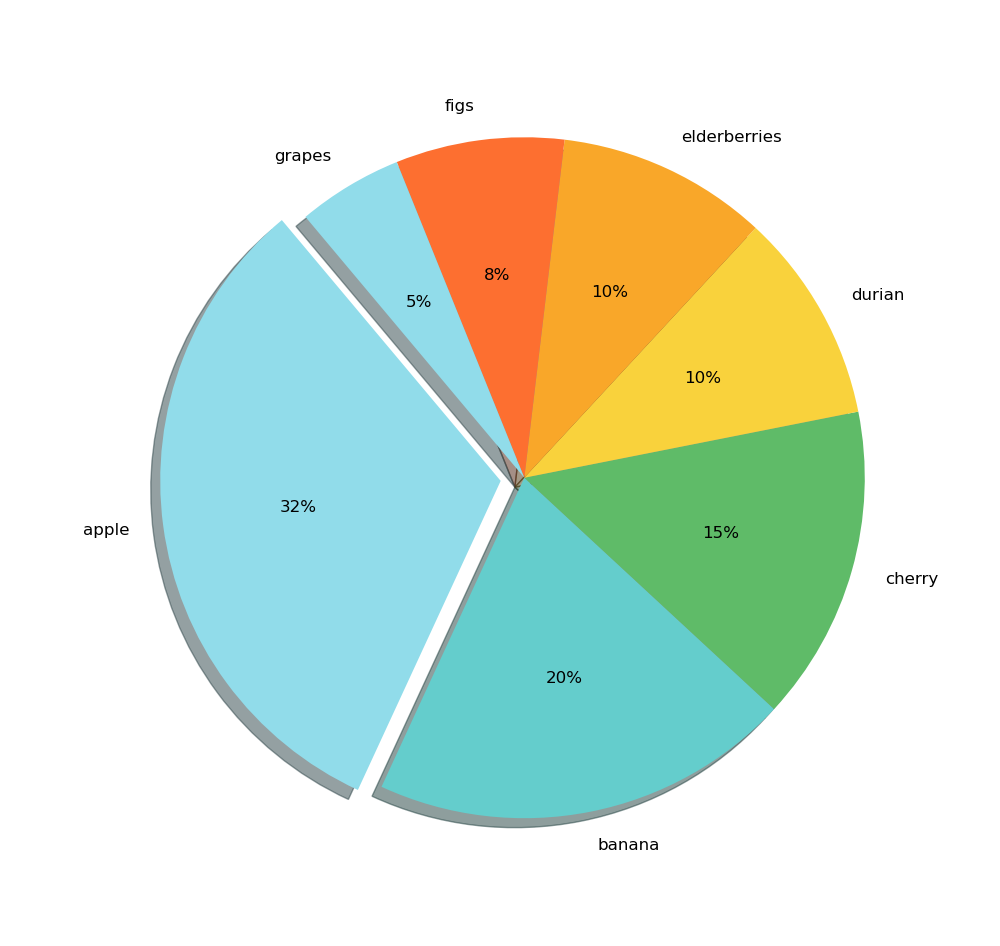
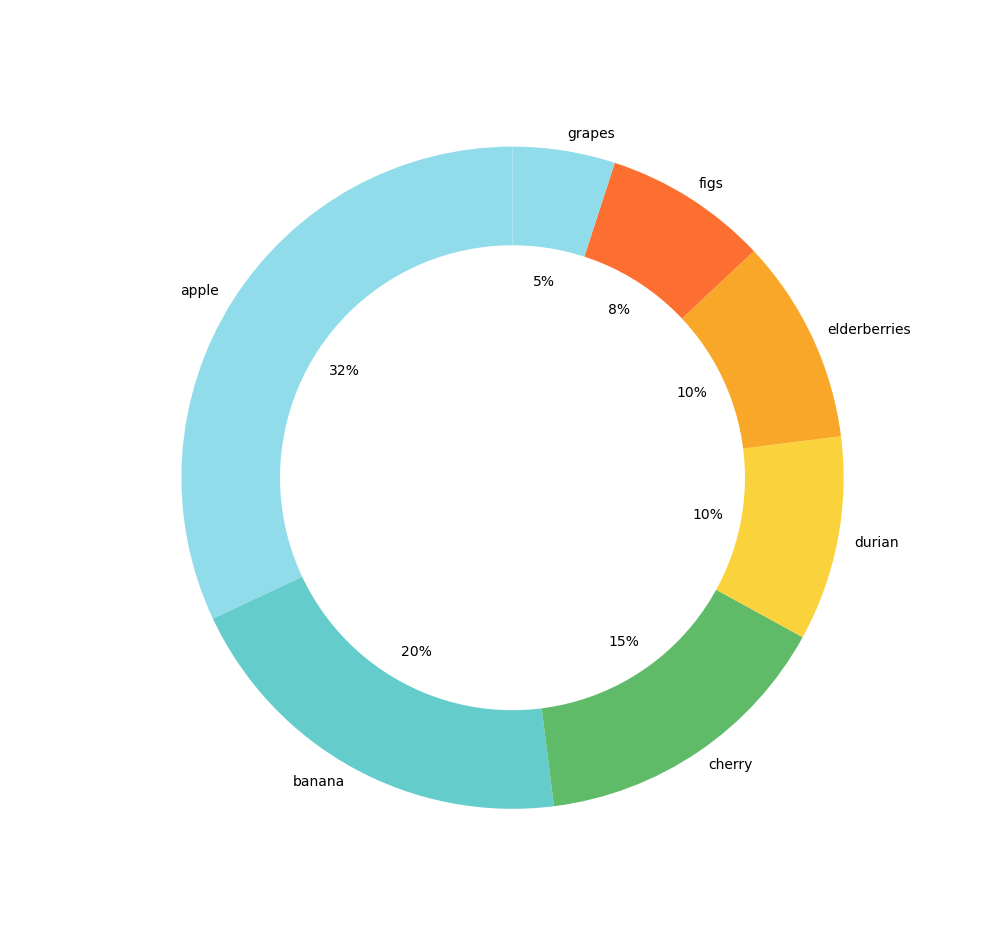
Un best practice est de ne jamais utiliser une dimension contenant plus de 7 valeurs différentes car l'interprétation devient plus difficile d'un point de vue cognitif et il vaut mieux dans ce cas passer sur un bar chart.
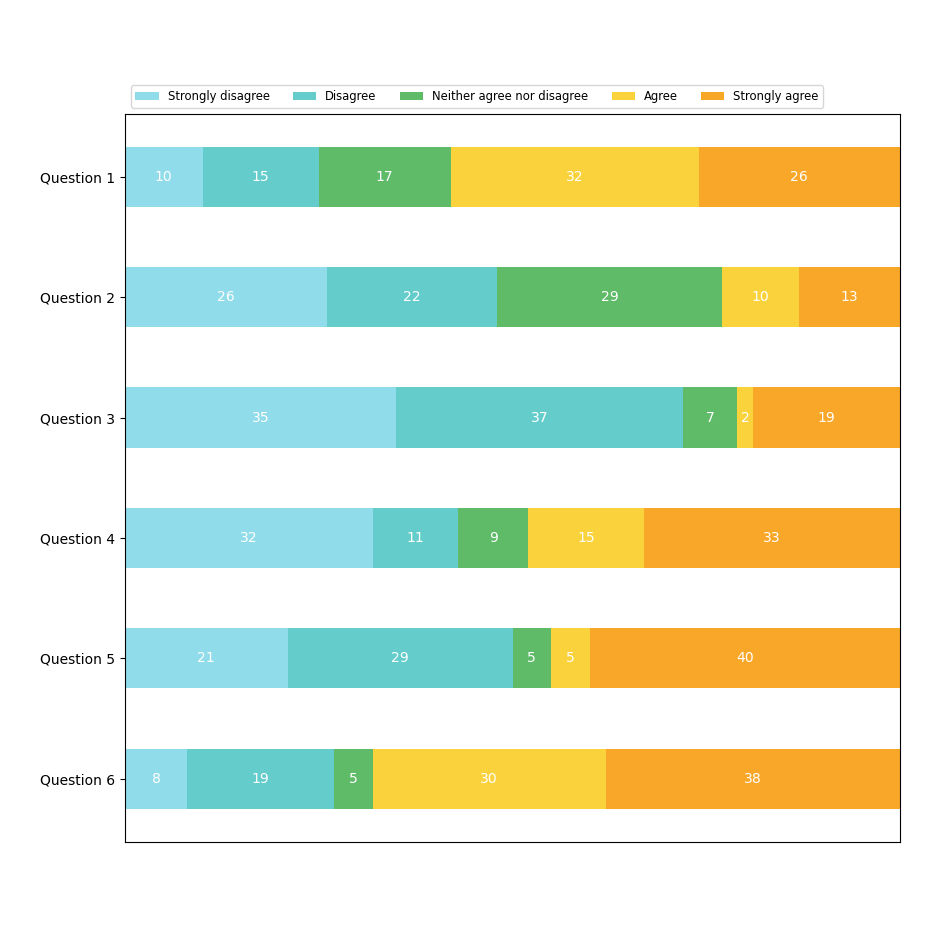
Les visualisations de distribution
Les visualisation de distribution sont utilisées pour mettre en avant la façon dont des valeurs quantitatives sont distribuées le long d'un axe. Ces graphiques permettent de facilement d'identifier les valeurs les plus hautes et les plus basses, d'avoir une idée de la forme de distribution, de mettre en avant les valeurs descriptives de base telles que la mediane, la moyenne ou le mode ; d'identifier les valeurs aberrantes ;
Codes visualisations python
Vous cherchez un viseul spécifique en python ? Trouvez un maximum de visuels avec exemples sur Python Graph Gallery ( Sélectionnez Chart Types ).
Bar Chart
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 10))
fruits = ['apple', 'blueberry', 'cherry', 'orange']
counts = [40, 100, 30, 55]
bar_labels = ['red', 'blue', '_red', 'orange']
colors = ['#91DCEA', '#64CDCC', '#5FBB68', '#F9D23C', '#F9A729', '#FD6F30']
combined = sorted(zip(counts, fruits, bar_labels, colors), reverse=True)
counts, fruits, bar_labels, colors = zip(*combined)
bars = ax.bar(fruits, counts, label=bar_labels, color=colors[:len(fruits)])
ax.bar_label(bars, label_type='edge')
ax.set_ylabel('Fruit supply')
ax.set_title('Fruit supply by kind and color')
plt.show()
Line Chart
import matplotlib.pyplot as plt
day = ['Mon','Tue','Wed','Thu','Fri','Sat','Sun']
#sales_product1 = [250,350,265,150,320,450,200]
sales_product2 = [300, 280, 350, 200, 400, 380, 250]
colors = ['#91DCEA', '#64CDCC', '#5FBB68',
'#F9D23C', '#F9A729', '#FD6F30']
plt.figure(figsize=(10, 10))
#plt.plot(day, sales_product1, color='#F9A729', marker='o', label='Product 1')
plt.plot(day, sales_product2, color='#64CDCC', marker='s', label='Product 2')
#for i, sale in enumerate(sales_product1):
#plt.annotate(str(sale), (day[i], sale), textcoords="offset points", xytext=(0,10), ha='center')
for i, sale in enumerate(sales_product2):
plt.annotate(str(sale), (day[i], sale), textcoords="offset points", xytext=(0,-10), ha='center')
plt.ylabel('Sales')
plt.title('Sales by weekday')
plt.ylim(0, 500)
plt.show()
Bar Chart Grouped
import matplotlib.pyplot as plt
import numpy as np
species = ("Adelie", "Gentoo")
penguin_means = {
'Bill Depth': (18.35, 14.98),
'Bill Length': (38.79, 47.50),
'Flipper Length': (189.95, 217.19),
}
x = np.arange(len(species))
width = 0.25
multiplier = 0
colors = ['#91DCEA', '#64CDCC', '#5FBB68', '#F9D23C', '#F9A729', '#FD6F30']
fig, ax = plt.subplots(figsize=(10, 10))
for i, (attribute, measurement) in enumerate(penguin_means.items()):
offset = width * multiplier
rects = ax.bar(x + offset, measurement, width, label=attribute, color=colors[i % len(colors)])
ax.bar_label(rects, padding=3)
multiplier += 1
ax.set_ylabel('Length (mm)')
ax.set_title('Penguin attributes by species')
ax.set_xticks(x + width, species)
ax.legend(loc='upper left', ncols=3)
#ax.set_ylim(0, 250)
plt.show()
Line Chart Grouped
# LineChart python
import matplotlib.pyplot as plt
day = ['Mon','Tue','Wed','Thu','Fri','Sat','Sun']
sales_product1 = [250,350,265,150,320,450,200]
sales_product2 = [300, 280, 350, 200, 400, 380, 250]
colors = ['#91DCEA', '#64CDCC', '#5FBB68',
'#F9D23C', '#F9A729', '#FD6F30']
plt.figure(figsize=(10, 10))
plt.plot(day, sales_product1, color='#F9A729', marker='o', label='Product 1')
plt.plot(day, sales_product2, color='#64CDCC', marker='s', label='Product 2')
for i, sale in enumerate(sales_product1):
plt.annotate(str(sale), (day[i], sale), textcoords="offset points", xytext=(0,10), ha='center')
for i, sale in enumerate(sales_product2):
plt.annotate(str(sale), (day[i], sale), textcoords="offset points", xytext=(0,-10), ha='center')
plt.ylabel('Sales')
plt.title('Sales by weekday')
plt.ylim(0, 500)
plt.show()
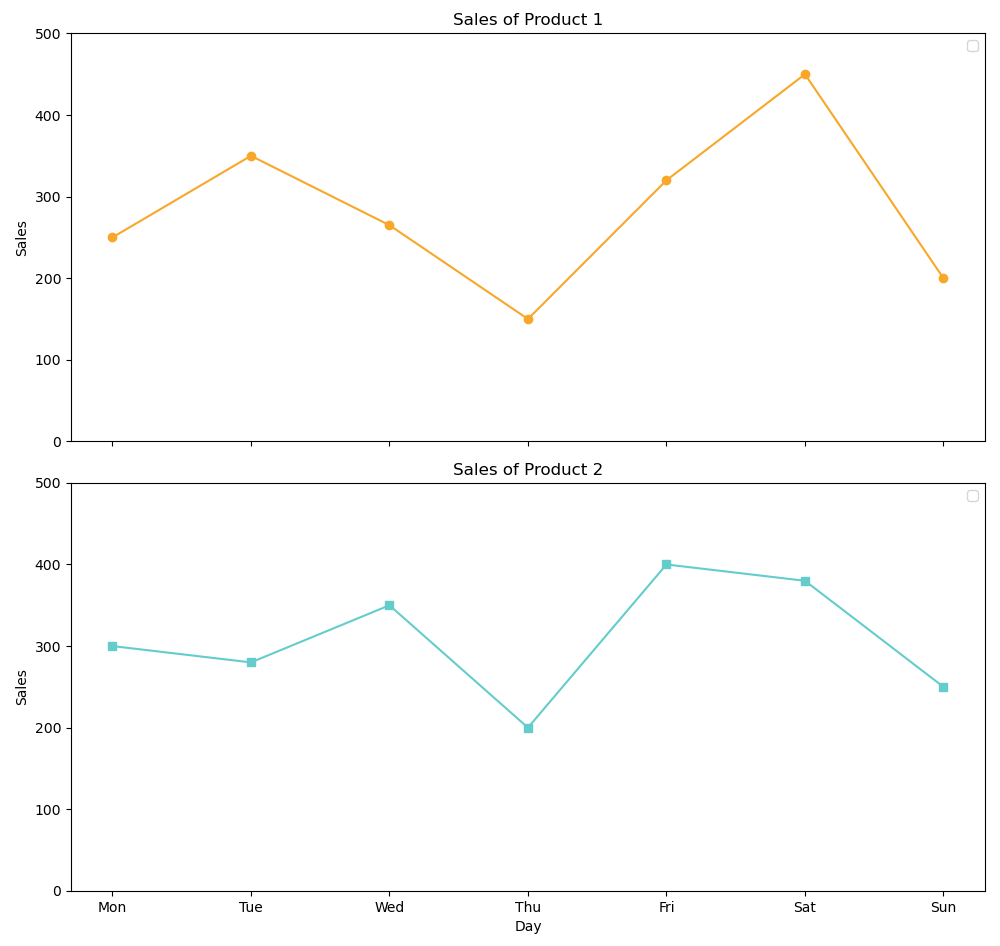
Treilli Line Chart
# Treilli Line Chart python
import matplotlib.pyplot as plt
day = ['Mon','Tue','Wed','Thu','Fri','Sat','Sun']
sales_product1 = [250, 350, 265, 150, 320, 450, 200]
sales_product2 = [300, 280, 350, 200, 400, 380, 250]
fig, (ax1, ax2) = plt.subplots(nrows=2, ncols=1, figsize=(10, 10), sharex=True)
ax1.plot(day, sales_product1, color='#F9A729', marker='o')
ax1.set_ylabel('Sales')
ax1.set_title('Sales of Product 1')
ax1.set_ylim(0, 500)
ax1.legend()
ax2.plot(day, sales_product2, color='#64CDCC', marker='s')
ax2.set_xlabel('Day')
ax2.set_ylabel('Sales')
ax2.set_title('Sales of Product 2')
ax2.set_ylim(0, 500)
ax2.legend()
plt.tight_layout()
plt.show()
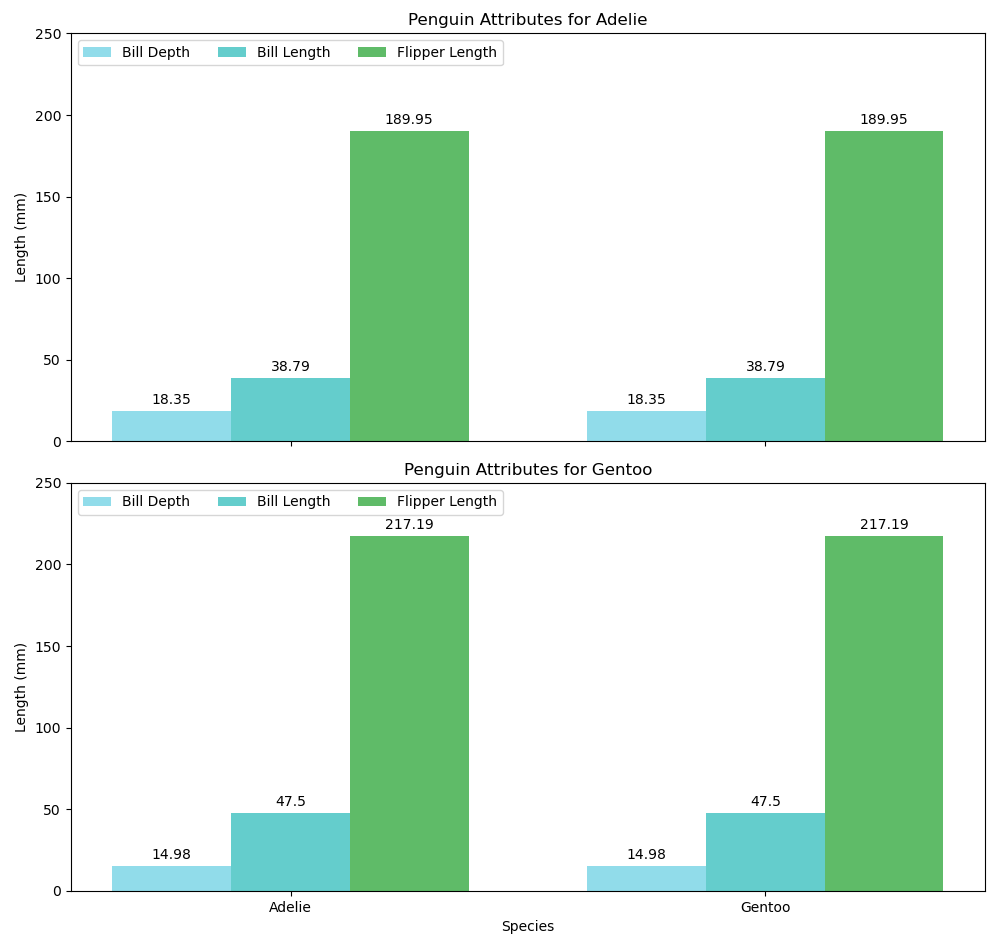
Treilli Bar Chart
# TrelliB Bar Chart Python
import matplotlib.pyplot as plt
import numpy as np
species = ("Adelie", "Gentoo")
penguin_means = {
'Bill Depth': (18.35, 14.98),
'Bill Length': (38.79, 47.50),
'Flipper Length': (189.95, 217.19),
}
x = np.arange(len(species))
width = 0.25
colors = ['#91DCEA', '#64CDCC', '#5FBB68', '#F9D23C', '#F9A729', '#FD6F30']
fig, (ax1, ax2) = plt.subplots(nrows=2, ncols=1, figsize=(10, 10), sharex=True)
for i, (attribute, measurement) in enumerate(penguin_means.items()):
rects = ax1.bar(x + i * width, [measurement[0]], width, label=attribute, color=colors[i % len(colors)])
ax1.bar_label(rects, padding=3)
ax1.set_ylabel('Length (mm)')
ax1.set_title('Penguin Attributes for Adelie')
ax1.set_xticks(x + width, species)
ax1.legend(loc='upper left', ncols=3)
ax1.set_ylim(0, 250)
for i, (attribute, measurement) in enumerate(penguin_means.items()):
rects = ax2.bar(x + i * width, [measurement[1]], width, label=attribute, color=colors[i % len(colors)])
ax2.bar_label(rects, padding=3)
ax2.set_xlabel('Species')
ax2.set_ylabel('Length (mm)')
ax2.set_title('Penguin Attributes for Gentoo')
ax2.set_xticks(x + width, species)
ax2.legend(loc='upper left', ncols=3)
ax2.set_ylim(0, 250)
plt.tight_layout()
plt.show()
Scatter Plot
# Scatter plot python
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from matplotlib.colors import ListedColormap
np.random.seed(19680801)
N = 50
x = np.random.rand(N)
y = np.random.rand(N)
z = np.random.rand(N)
color_dimension = pd.qcut(z, 3, labels=False)
area = (30 * np.random.rand(N))**2
colors = ['#91DCEA', '#64CDCC', '#5FBB68']
cmap = ListedColormap(colors)
fig, ax = plt.subplots(figsize=(10, 10))
scatter = ax.scatter(x, y, s=area, c=color_dimension, alpha=0.5, cmap=cmap)
plt.show()
Sankey Chart
# Sankey Chart python
import plotly.graph_objects as go
colors = ['#91DCEA', '#64CDCC', '#5FBB68', '#F9D23C', '#F9A729', '#FD6F30']
fig = go.Figure(data=[go.Sankey(
node = dict(
pad = 15,
thickness = 20,
line = dict(color = "black", width = 0.5),
label = ["A1", "A2", "B1", "B2", "C1", "C2"],
color = colors
),
link = dict(
source = [0, 0, 1, 2, 3, 3],
target = [2, 3, 3, 4, 4, 5],
value = [8, 2, 4, 8, 4, 2],
))])
fig.update_layout(
title_text=" Sankey Chart",
font_size=10,
width=1200,
height=1200
)
fig.show()
Pie Chart
# Pie Chart python
import matplotlib.pyplot as plt
labels = 'apple', 'banana', 'cherry', 'durian', 'elderberries', 'figs', 'grapes'
sizes = [32, 20, 15, 10, 10, 8, 5]
colors = ['#91DCEA', '#64CDCC', '#5FBB68',
'#F9D23C', '#F9A729', '#FD6F30']
plt.figure(figsize=(10, 10))
p = plt.pie(sizes, labels=labels, colors=colors, explode=(0.07, 0, 0, 0, 0, 0, 0),
autopct='%1.0f%%', startangle=130, shadow=True)
plt.axis('equal')
for i, (apple, banana, cherry, durian, elderberries, figs, grapes) in enumerate(p):
if i > 0:
apple.set_fontsize(12)
banana.set_fontsize(12)
cherry.set_fontsize(12)
durian.set_fontsize(12)
elderberries.set_fontsize(12)
figs.set_fontsize(12)
grapes.set_fontsize(12)
plt.show()
Donnut Chart
# Donnut Chart python
import matplotlib.pyplot as plt
labels = 'apple', 'banana', 'cherry', 'durian', 'elderberries', 'figs', 'grapes'
sizes = [32, 20, 15, 10, 10, 8, 5]
my_circle = plt.Circle((0, 0), 0.7, color='white')
colors = ['#91DCEA', '#64CDCC', '#5FBB68',
'#F9D23C', '#F9A729', '#FD6F30']
plt.figure(figsize=(10, 10))
d = plt.pie(sizes, labels=labels,colors=colors, autopct='%1.0f%%',
startangle=90, labeldistance=1.05)
plt.axis('equal')
plt.gca().add_artist(my_circle)
plt.show()
Bar Chart Stacked 100 %
# Stacked Bar CHart 100% python
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.colors as mcolors
category_names = ['Strongly disagree', 'Disagree',
'Neither agree nor disagree', 'Agree', 'Strongly agree']
results = {
'Question 1': [10, 15, 17, 32, 26],
'Question 2': [26, 22, 29, 10, 13],
'Question 3': [35, 37, 7, 2, 19],
'Question 4': [32, 11, 9, 15, 33],
'Question 5': [21, 29, 5, 5, 40],
'Question 6': [8, 19, 5, 30, 38]
}
colors = ['#91DCEA', '#64CDCC', '#5FBB68', '#F9D23C', '#F9A729']
def survey(results, category_names):
labels = list(results.keys())
data = np.array(list(results.values()))
data_cum = data.cumsum(axis=1)
fig, ax = plt.subplots(figsize=(10, 10))
ax.invert_yaxis()
ax.xaxis.set_visible(False)
ax.set_xlim(0, np.sum(data, axis=1).max())
for i, (colname, color) in enumerate(zip(category_names, colors)):
widths = data[:, i]
starts = data_cum[:, i] - widths
rects = ax.barh(labels, widths, left=starts, height=0.5,
label=colname, color=color)
r, g, b = mcolors.to_rgb(color)
text_color = 'white' if r * g * b < 0.5 else 'darkgrey'
ax.bar_label(rects, label_type='center', color=text_color)
ax.legend(ncols=len(category_names), bbox_to_anchor=(0, 1),
loc='lower left', fontsize='small')
return fig, ax
survey(results, category_names)
plt.show()
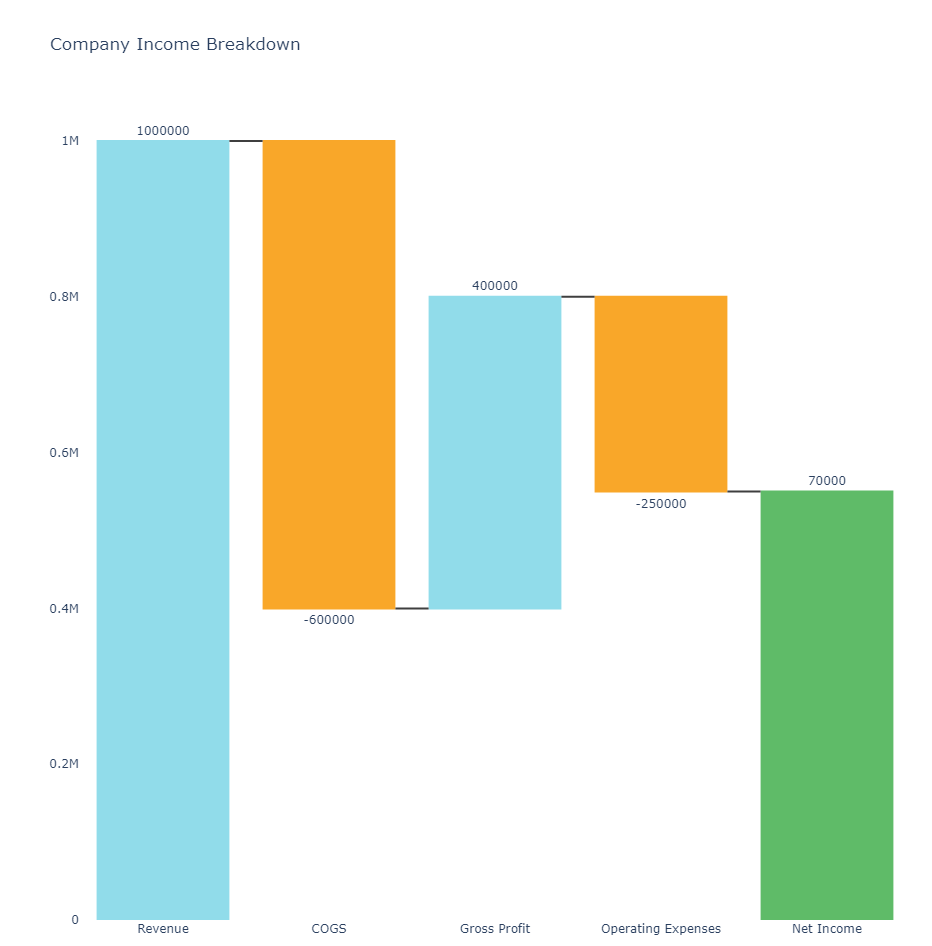
Waterfall
# waterfall python
import plotly.graph_objects as go
categories = ['Revenue', 'COGS', 'Gross Profit', 'Operating Expenses', 'Net Income']
values = [1000000, -600000, 400000, -250000, 70000]
colors = ['#91DCEA', '#64CDCC', '#5FBB68', '#F9D23C', '#F9A729', '#FD6F30']
cumulative_values = [0]
for value in values:
cumulative_values.append(cumulative_values[-1] + value)
fig = go.Figure(go.Waterfall(
name = "20",
orientation = "v",
measure = ["relative"] * (len(values) - 1) + ["total"],
x = categories,
textposition = "outside",
text = values,
y = values,
connector = {"line":{"color":"rgb(63, 63, 63)"}},
increasing = {"marker":{"color": '#91DCEA'}},
decreasing = {"marker":{"color": '#F9A729'}},
totals = {"marker":{"color": '#5FBB68'}}
))
fig.update_layout(
title = "Company Income Breakdown",
showlegend = True,
width=1000,
height=1000,
plot_bgcolor='white'
)
fig.show()
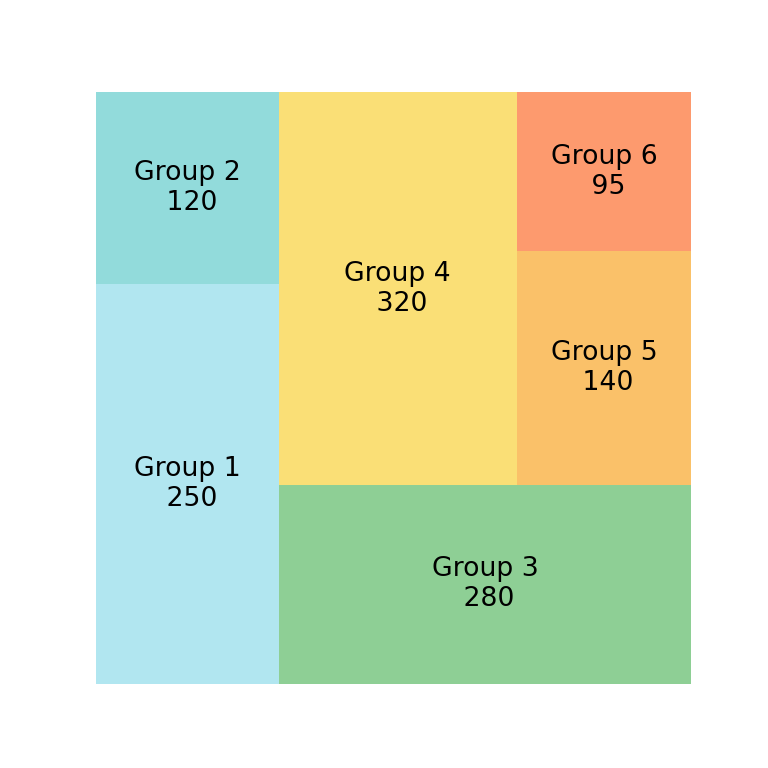
Treemap
# Tree Map python
import matplotlib.pyplot as plt
import squarify # pip install squarify
import pandas as pd
colors = ['#91DCEA', '#64CDCC', '#5FBB68',
'#F9D23C', '#F9A729', '#FD6F30']
df = pd.DataFrame({'nb_people':[8,3,4,2], 'group':["group A", "group B", "group C", "group D"] })
squarify.plot(sizes=df['nb_people'],color=colors, label=df['group'], alpha=.8 )
plt.axis('off')
plt.show()
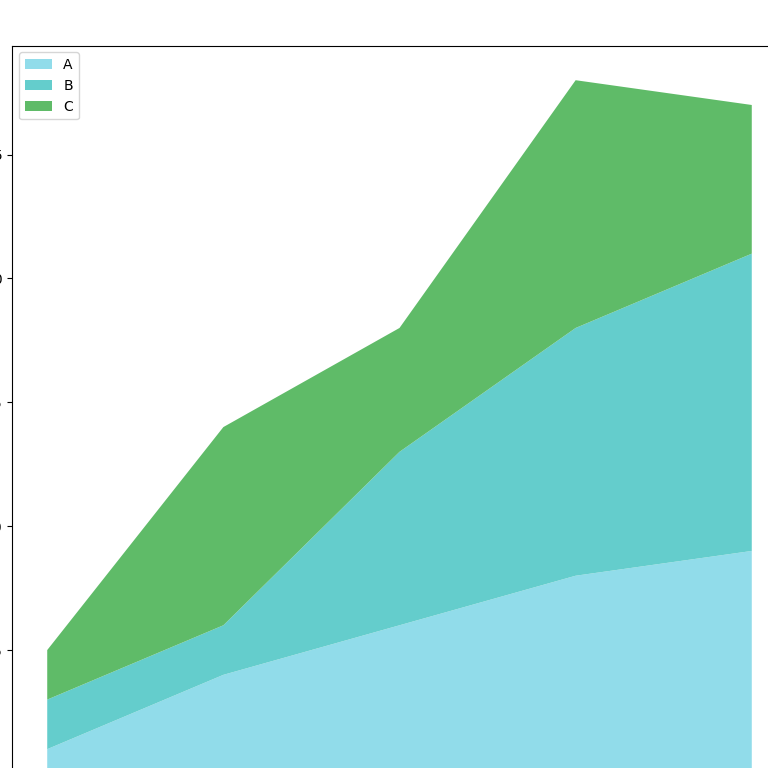
Line Chart Stacked
# Stacked Line Chart python
import numpy as np
import matplotlib.pyplot as plt
x=range(1,6)
y=[ [1,4,6,8,9], [2,2,7,10,12], [2,8,5,10,6] ]
colors = ['#91DCEA', '#64CDCC', '#5FBB68',
'#F9D23C', '#F9A729', '#FD6F30']
plt.figure(figsize=(10, 10))
plt.stackplot(x,y, labels=['A','B','C'], colors=colors)
plt.legend(loc='upper left')
plt.show()
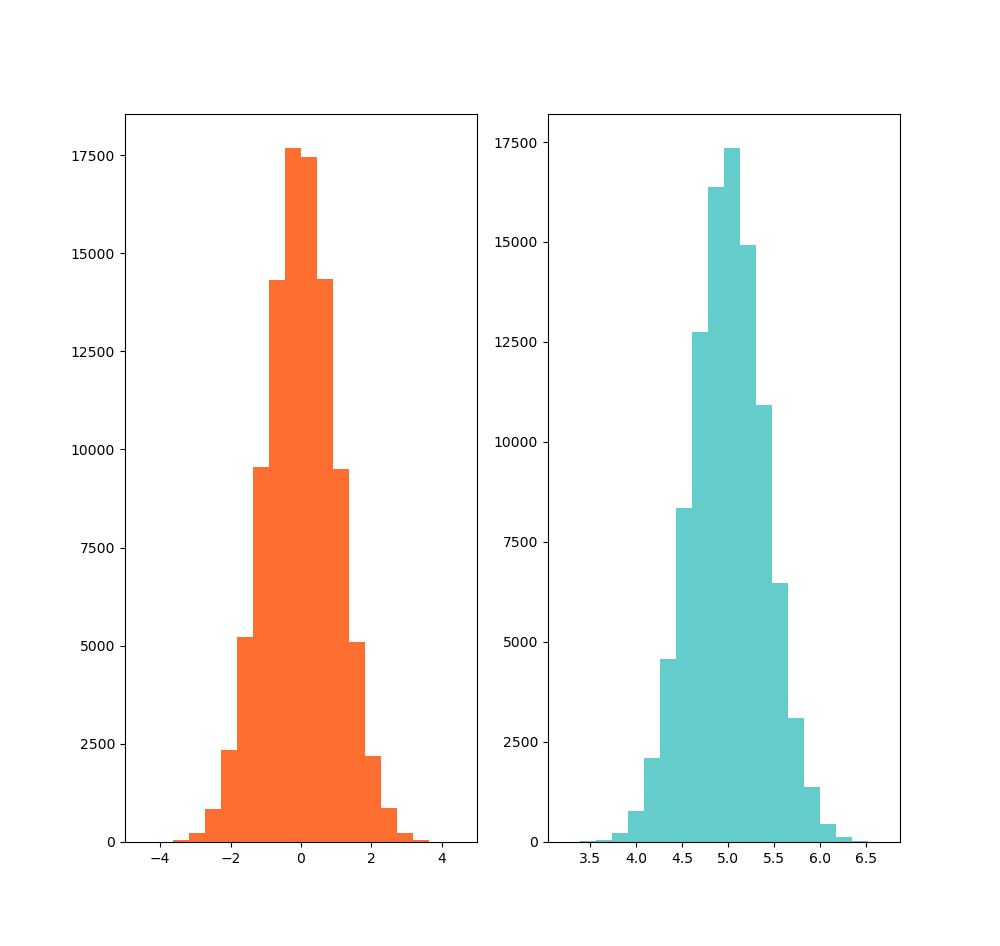
Histogram
# Histogram python
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import colors
from matplotlib.ticker import PercentFormatter
rng = np.random.default_rng(19680801)
N_points = 100000
n_bins = 20
dist1 = rng.standard_normal(N_points)
dist2 = 0.4 * rng.standard_normal(N_points) + 5
fig, axs = plt.subplots(1, 2,figsize=(10, 10))
axs[0].hist(dist1, bins=n_bins, color='#FD6F30')
axs[1].hist(dist2, bins=n_bins, color='#64CDCC')
plt.show()
Candles
# Candles python
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(19680801)
fruit_weights = [
np.random.normal(130, 10, size=100),
np.random.normal(125, 20, size=100),
np.random.normal(120, 30, size=100),
]
labels = ['peaches', 'oranges', 'tomatoes']
colors = ['#91DCEA', '#F9D23C', '#F9A729']
fig, ax = plt.subplots()
ax.set_ylabel('fruit weight (g)')
bplot = ax.boxplot(fruit_weights,
patch_artist=True)
ax.set_xticklabels(labels)
for patch, color in zip(bplot['boxes'], colors):
patch.set_facecolor(color)
plt.show()