The World of Data
The emergence of conversational agents using a model known as generative artificial intelligence represents a certain evolution in the adoption of machine learning by the general population and most companies.
The statistical approaches used to create such models have existed since the mid-20th century. However, this evolution - the reproduction of a conversation close to human capabilities, or even better in some cases - is strongly linked to the democratization of new technologies, particularly GPUs ( Graphic Processing Units ), which enable efficient calculations and thus the creation of complex models. Like any disruptive event in the evolution of society, the emergence of this new technology has led to a form of « bubble » around the very concept of artificial intelligence.
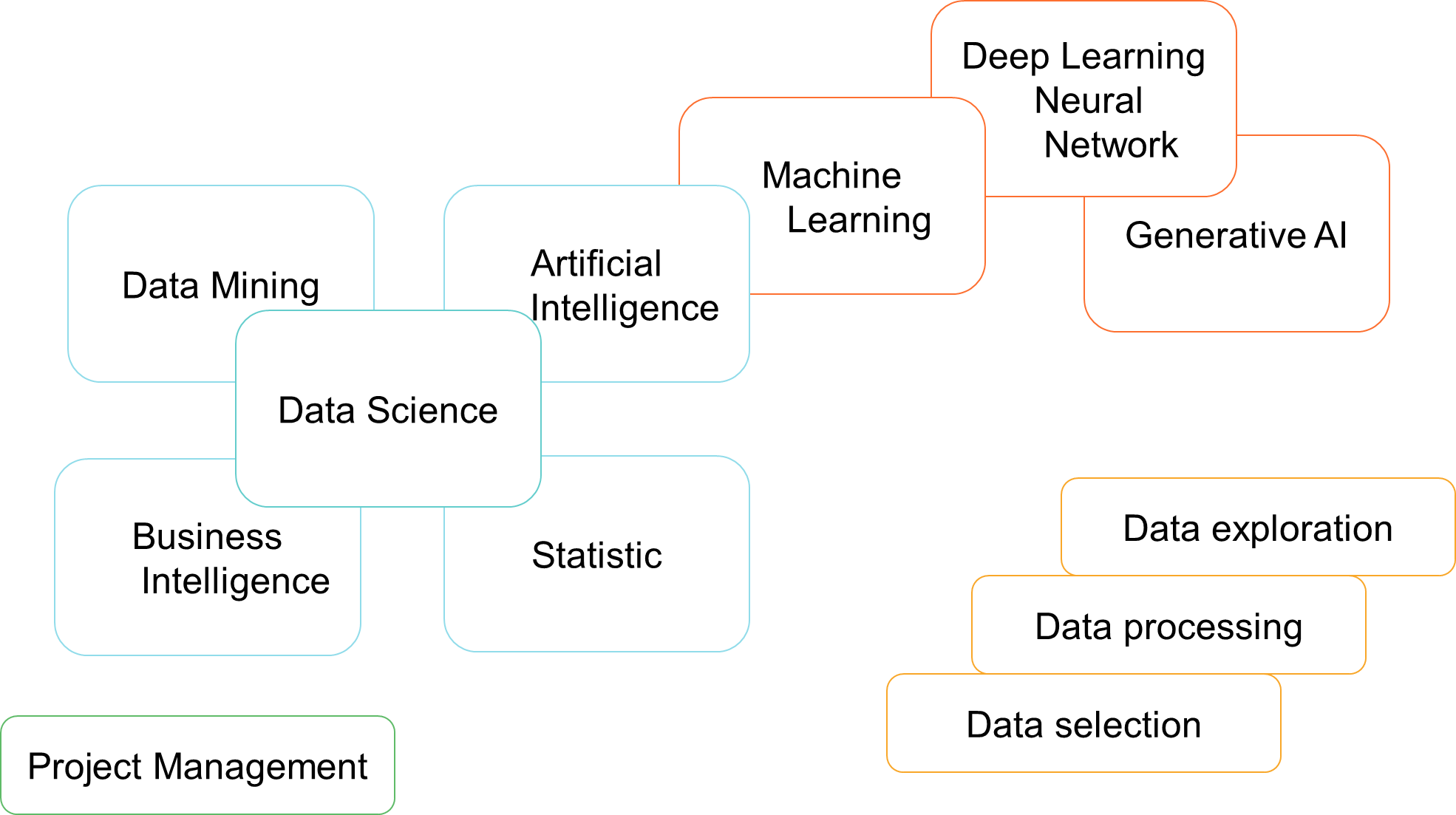
In this first section, we will better understand what machine learning is and, above all, democratize certain terminology related to this field in order to demystify the concept and understand the relationships and differences between artificial intelligence, machine learning, neural networks or deep learning, statistics and mathematics, as well as business intelligence.
They all have one thing in common : they are part of the broader field of data science.
Artificial Intelligence
« We marveled at our own magnificence by giving birth to AI ! ». This quote comes from the science-fiction movie « Matrix » released in 1999. The directors were not particularly ahead of their time on the subject. In fact, artificial intelligence, or at least the use of the term, appeared in 1956 thanks to two pioneers in the field : John McCarthy & Marvin Lee Minsky.
However, this term has gained significant prominence in recent years with the emergence of so-called « NLP » models for Natural Language Processing, which enable interactions between computers and humans using natural language.
In 1956, artificial intelligence was defined as « the construction of computer programs that engage in tasks that are currently performed more satisfactorily by humans because they require high-level mental processes such as perceptual learning, memory organization, and critical reasoning ».
We find two fundamental notions : general artificial intelligence ( AGI ), which would be an AI capable of performing or learning cognitive tasks that have so far been unique to humans or animals, and weak artificial intelligence ( Narrow AI ).
The literature on this subject is diverse. The term AI has become so widespread that many articles define weak ( or simple ) AI as the basic concept of what is actually machine learning, and define general AI as, for example, natural language models between computers and humans.
However, many authors, with whom I agree, point out that the definition of intelligence includes notions of logic, self-awareness, learning, emotional intelligence, and creativity. We use the following definition of artificial intelligence :
📝 « A set of theories and techniques for developing complex computer programs capable of simulating certain aspects of human intelligence ( reasoning, learning… ) ».
Machine Learning
The definition of artificial intelligence highlights a fundamental concept often forgotten : machine learning is a form of artificial intelligence. Indeed, it is a field of study within artificial intelligence, particularly learning, which is defined as :
📝 « Programming machines so that they can learn from data to automate complex tasks »..
Doing « machine learning » is ultimately taking on the role of a teacher for a computer and teaching it to perform a task based on data—making it intelligent. Whether it involves supervised techniques ( where the machine is trained on labeled data ) or unsupervised techniques ( feeding a computer data and programming it to perform a task, such as segmenting data ), in both cases, the computer learns to the point where, after completing its training, it will learn new rules on its own.
The literature often cites the example of programming a computer to identify incoming emails as either spam or non-spam. In this example, we teach the computer that when it encounters certain words in an email ( e.g. « free », « lottery », « money » ), there is a high probability that it is SPAM. Conversely, when it identifies the words « friend », « dinner », « sincerely » in an email, there is a high probability that it is non-spam ( an authorized email ).
The computer has learned and will now classify emails as either Spam or non-Spam. What is interesting in machine learning is that when we stop being a teacher for the machine, it will continue to learn and define rules. For example, the machine may identify that in most spam identified by the combination or partial combination of the words « free », « lottery », and « money », the word « bitcoin » frequently appears. From now on, the machine will consider the word « bitcoin » as an indicator in the probability of classifying an email as spam.
Deep Learning
Deep learning is defined as :
📝 « A type of machine learning based on artificial neural networks in which multiple layers of processing are used to extract data features at progressively higher levels ».
According to this definition, we understand that it is a machine learning technique that relies on a specific model : neural networks.
We have always operated by mimicking what nature offers us, and in the case of neural networks, humans have attempted to replicate the functioning of a human brain in a computer. However, it is important to remember that even though science makes major advances every year, medicine still does not fully understand all the concepts of how the human brain works, which is why strong artificial intelligence cannot yet exist.
Moreover, if we have made significant advances in what is known as weak AI in recent years, it is partly thanks to two key ingredients : on the one hand, the amount of available data to process, which improves learning, and on the other hand, the evolution of graphics cards and the emergence of GPUs ( Graphic Processing Units ), which are computer chips added to graphics cards to optimize image rendering. These GPUs can also be used to perform a set of calculations simultaneously, thereby freeing up the CPU ( central processing unit ).
These simultaneous calculations have allowed for the efficient use of one of the most promising machine learning algorithms, namely neural networks. However, if we zoom in on the functioning of a neural network and isolate the functioning of each neuron, we find what we had at the origin of machine learning, namely linear regression or logistic regression. Each activation function of a neuron could indeed be compared to linear regression or logistic regression, which in turn will activate another function. Of course, the evolution and optimization of such models have allowed us to develop more adapted functions ( RELU, Softmax ) depending on the cases and whether we are in hidden layers or an output layer of a network.
This algorithm is promising because it uses GPUs, making the calculation very fast and less resource-intensive for a machine. It accepts all types of data ( structured, semi-structured, and even unstructured (audio, image,...) ) and, above all, as a parametric model ( cf. linear and logistic regression ), it allows the use of a faster training optimization method than gradient descent to find the local optimum, namely the Adam optimization algorithm.
There is also a peculiarity that distinguishes neural networks from all other models used in machine learning : the way it processes data in hidden layers is not identifiable.
Statistics
At the foundation of everything is statistics, a field of mathematics. To perform learning, machine learning ( also known as automatic learning, artificial learning, or statistical learning ) draws its foundations from statistical approaches.
Statistics is defined as :
📝 « A set of methods that aim to collect, process, and interpret data ».
To better understand the link between machine learning and statistics, it is important to mention two additional concepts : the roles and differences between an algorithm and a model in machine learning.
An algorithm represents the entire procedure applied to data to create a machine learning model. The model is what the machine has learned and is applied to data, while the algorithm is the development of its learning, which is carried out using statistical and mathematical approaches.
We will therefore use techniques that have existed since the mid-20th century and are derived from statistics ( linear regression, logistic regression, neural networks, K-Nearest-Neighbors, Naive Bayes classifier, anomaly detection, principal component analysis, association rules, clustering, collaborative filtering,... ), applied to large datasets using powerful machines, and as part of the procedure, which will ultimately be able to maintain continuous learning, i.e., create new rules or highlight new hidden trends. This is why a machine learning model must be reviewed, corrected, and adapted continuously.
Business Intelligence
Business intelligence, also known as BI, is also part of the data science family. It also uses statistics.
📝 BI refers to the technologies, applications, and practices used to collect, integrate, analyze, and present information. It is a decision support system..
Business intelligence uses tools, most of which offer complete solutions for connecting and extracting information from one or more data sources, transforming and preparing this information to make it usable, modeling data to improve query efficiency, and finally applying data visualization techniques to present the information in a clear and concise manner, enabling informed decision-making.
In contrast to machine learning, business intelligence is limited to the exploitation of structured or semi-structured data and does not allow predictions on multivariate data. Business intelligence helps with strategic planning for the company and answers the questions: « What are my company's current performance metrics? and what were my company's past performance metrics ? ».
Business intelligence tools are increasingly automated, especially through machine learning models, to help users analyze data, make choices on visualizations, and even create « on-demand » visualizations based on a voice query.