Anomaly Detection
Anomaly detection is an unsupervised technique where learning consists of examining a dataset considered to represent normal events in order to detect an abnormal event.
Some of the diagrams and concepts presented here are inspired by the Machine Learning course by Andrew Ng, a program created in collaboration between Stanford University Online Education and DeepLearning.AI, available on Coursera. Find the original course here: Machine Learning by Andrew Ng.
Take the example of a factory that produces airplane engines, where the final test involves running each engine and measuring the vibrations and temperature.
We have two variables : generated heat and vibration intensity, as well as values for all the tests performed on engines considered to be normal.
We have values for a new record .
The idea behind anomaly detection is to determine whether the new engine's data is similar to the data from previously manufactured engines.
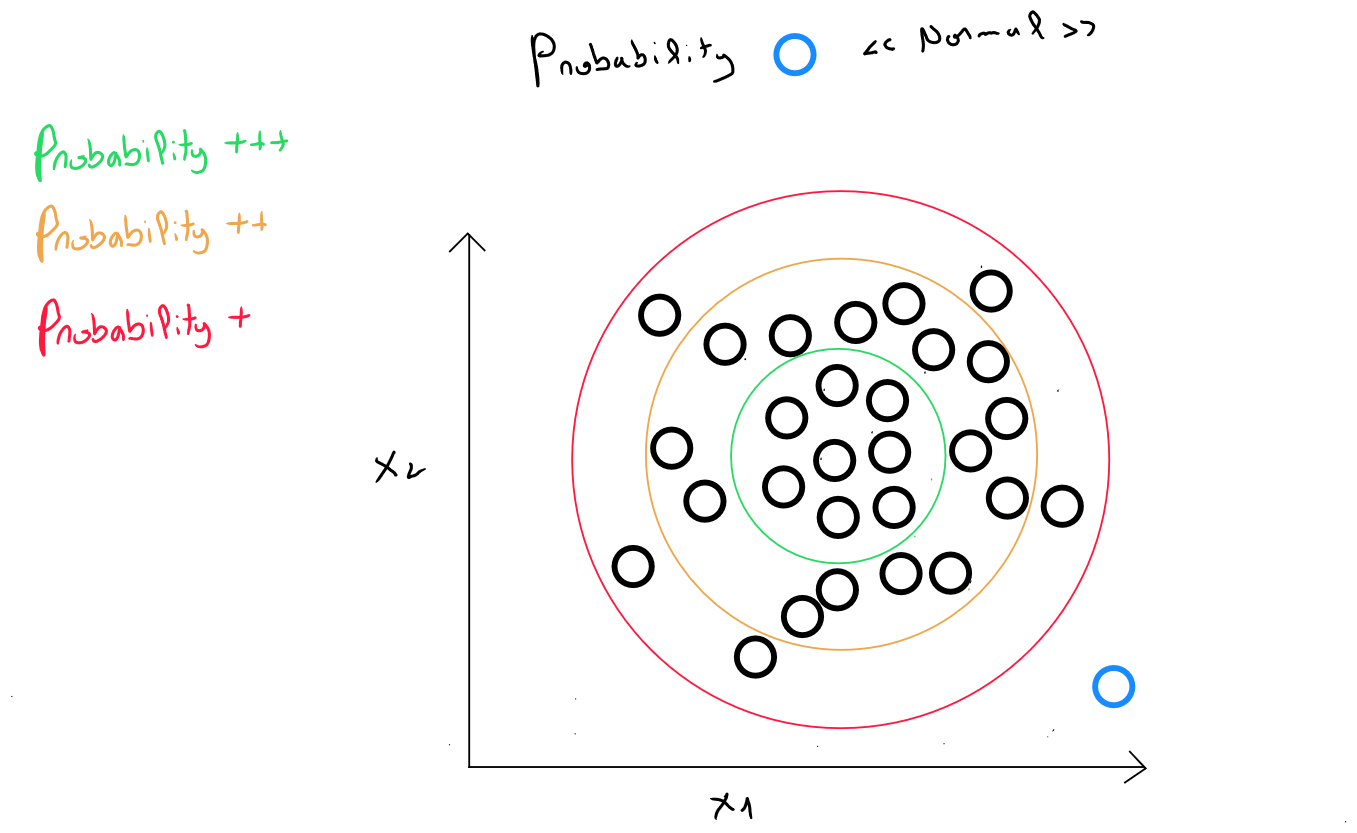
For anomaly detection, we have data : , and our model can be considered as the probability that new values exist within the « correct » data.
Anomaly detection works based on the Gaussian approximation principle. Essentially, this means that even if the data is not perfectly Gaussian, it can be approximated by a Gaussian distribution - at least for the majority of records - and anomalies are defined as points that are far from this majority.
Gaussian Distribution
A Gaussian distribution, also known as a bell curve, is symmetric around its mean. The mean defines the center of the distribution on the x-axis ( where the peak of the curve is located ), and the variance measures the dispersion of the data around the mean.
In a Gaussian distribution, the mean corresponds to both the mode and the median ( perfectly symmetric curve ).
As we discussed in the section on univariate statistical principles, variance measures the spread of values in a variable. It is calculated as the average of the squared differences from the mean and is always positive.
Variance is calculated as follows :
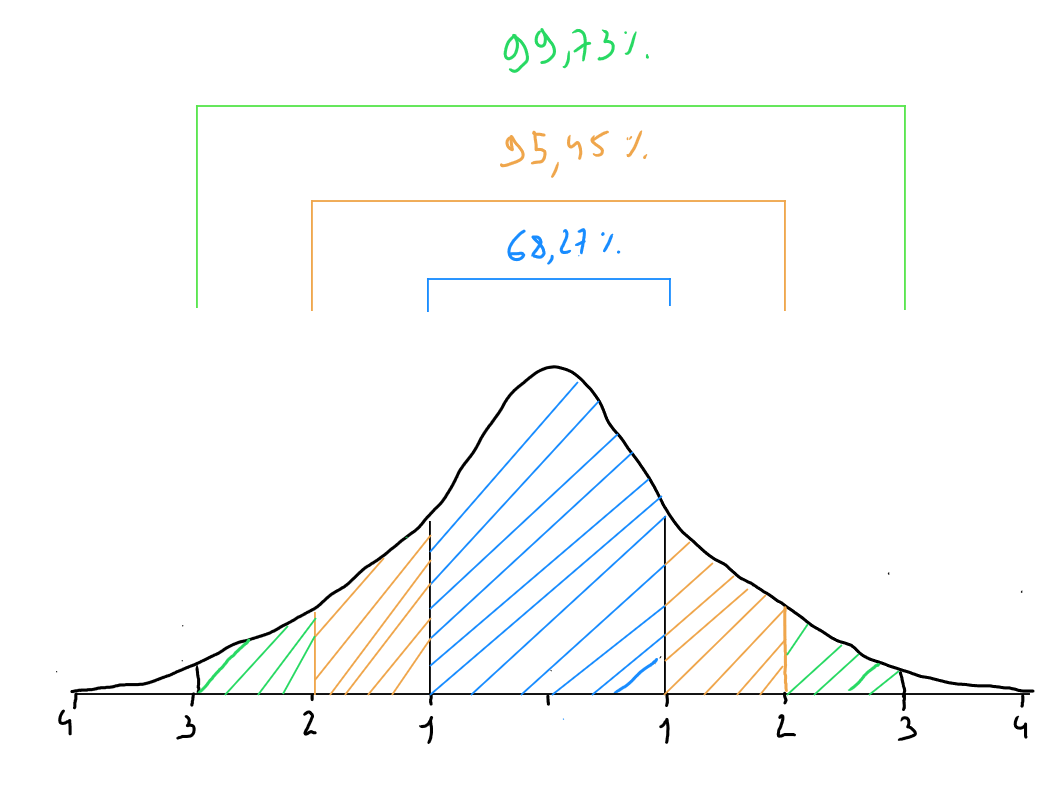
In a Gaussian distribution, the following empirical rule applies :
- of the data is within one standard deviation of the mean ;
- of the data is within two standard deviations of the mean ;
- of the data is within three standard deviations of the mean ;
Probability Density of a Normal Distribution
The probability density of a normal distribution indicates the relative probability that takes a value within a small interval around . Capital represents all possible outcomes of a variable, and lowercase is a specific value that can take. In other words, the probability density indicates how likely a random value is to be near another value.
The probability density formula for a normal distribution is :
Where corresponds to and is .
This probability density has the following properties :
- The sum of probabilities for all possible values of equals ;
- The density is symmetric around the mean . The probability is highest near and decreases as moves away from ;
- The tails of the distribution, representing extreme events, decrease very rapidly ;
Probability Densities of Different Features
In real-world anomaly detection, we deal with a record containing values for multiple variables. This means we're working with a multivariate distribution ( not univariate ). An anomaly may consist of a record in which some variables are consistent with the norm, but one particular variable is abnormal. To detect this abnormality, it's important to consider the independence of features and calculate the individual probability densities for each variable in a normal distribution, then multiply them together.
In practice, this involves applying the following formula :
This can be rewritten as :
We have values for a new record to which we apply our formula.
The rule is as follows :
- If < (a very small number), then anomaly ;
- If >= , then normal ;
We define a threshold ( epsilon ) to classify a record as normal or anomalous based on the probability density formula of features. is a very small number, assuming that of the data is within three standard deviations of the mean.
Defining the Threshold
To define , we split our data into a training and validation set. While this may resemble a supervised technique, a supervised technique would not be effective because anomaly detection typically involves very few « anomaly » cases, making it difficult for a parametric or non-parametric algorithm to predict accurately.
Let's consider the following example : we have 10,000 records containing values for manufactured airplane engines that showed no anomalies, and 20 records ( 20 engines ) for which anomalies were detected.
In this case :
- We split the data and train our model on 8,000 « normal » records. Training consists of calculating the Gaussian probability density for each record () ;
- We then sort these probabilities in descending order and select several values ( Gaussian probability density ) among the lowest ones ;
- These values are tested as the threshold ( epsilon ) on the remaining 2,000 validation records ( including 20 anomalies ), and we identify the value of that best distinguishes between anomalies and normal data without classifying normal data as anomalies ;
Feature Selection
So far, we have seen that our algorithm performs the following steps :
- Select features : ;
- Calculate parameters ;
- Given a new record for , calculate : or ;
- Result = if , anomaly; if , normal ;
One key condition is to have Gaussian-distributed variables. This condition is not always met, and there are ways to improve a distribution to make it more Gaussian :
- ;
- ;
- ;
- ;
- ;
- ;
Code Python
import numpy as np
import pandas as pd
from scipy.stats import norm
import matplotlib.pyplot as plt
#Synthetic data
np.random.seed(0)
x1 = np.random.normal(50, 10, 8000) # 8000 correct records x1 - average 50 ; standard deviation 10
x2 = np.random.normal(30, 5, 8000) # 8000 correct records x2 - average 30 ; standard deviation 5
# 2000 validation records (1980 normal, 20 not normal)
x1_val = np.random.normal(50, 10, 1980)
x2_val = np.random.normal(30, 5, 1980)
x1_val_anomalous = np.random.normal(80, 5, 20)
x2_val_anomalous = np.random.normal(10, 5, 20)
x1_val = np.concatenate([x1_val, x1_val_anomalous])
x2_val = np.concatenate([x2_val, x2_val_anomalous])
train_data = pd.DataFrame({
'x1': x1,
'x2': x2
})
val_data = pd.DataFrame({
'x1': x1_val,
'x2': x2_val,
'label': [0]*1980 + [1]*20 # 1 = Anomaly
})
mu_x1, sigma_x1 = np.mean(train_data['x1']), np.std(train_data['x1'])
mu_x2, sigma_x2 = np.mean(train_data['x2']), np.std(train_data['x2'])
def gaussian_probability_density(x, mu, sigma):
return (1 / (np.sqrt(2 * np.pi) * sigma)) * np.exp(-0.5 * ((x - mu) / sigma) ** 2)
train_data['p_x1'] = gaussian_probability_density(train_data['x1'], mu_x1, sigma_x1)
train_data['p_x2'] = gaussian_probability_density(train_data['x2'], mu_x2, sigma_x2)
train_data['p'] = train_data['p_x1'] * train_data['p_x2']
val_data['p_x1'] = gaussian_probability_density(val_data['x1'], mu_x1, sigma_x1)
val_data['p_x2'] = gaussian_probability_density(val_data['x2'], mu_x2, sigma_x2)
val_data['p'] = val_data['p_x1'] * val_data['p_x2']
epsilons = np.linspace(min(val_data['p']), max(val_data['p']), 1000)
best_epsilon = None
best_f1 = 0
for epsilon in epsilons:
predictions = val_data['p'] < epsilon
tp = np.sum((predictions == 1) & (val_data['label'] == 1))
fp = np.sum((predictions == 1) & (val_data['label'] == 0))
fn = np.sum((predictions == 0) & (val_data['label'] == 1))
if tp + fp == 0 or tp + fn == 0:
continue
precision = tp / (tp + fp)
recall = tp / (tp + fn)
f1 = 2 * precision * recall / (precision + recall)
if f1 > best_f1:
best_f1 = f1
best_epsilon = epsilon
print(f"Best Epsylon found: {best_epsilon}")
print(f"Best F1 Score: {best_f1}")
val_data['anomaly'] = val_data['p'] < best_epsilon
print(f"Detected anomaly: {val_data['anomaly'].sum()} sur {len(val_data)} enregistrements de validation")
plt.figure(figsize=(10, 6))
plt.scatter(val_data['x1'], val_data['x2'], c=val_data['anomaly'], cmap='coolwarm', marker='o')
plt.xlabel('Température (x1)')
plt.ylabel('Vibrations (x2)')
plt.title('Anomalies detection')
plt.show()