CRISP DM
CRISP-DM, the Cross-Industry Standard Process for Data Mining, is a methodology / process model that highlights the lifecycle of any data project. It consists of six phases, with a sequence that is not strictly fixed but suggested, allowing for flexibility. It's important to note that the application of this model is generally implemented in parallel with the SCRUM methodology. The CRISP-DM model is a general approach method, while the SCRUM framework ensures its successful implementation.
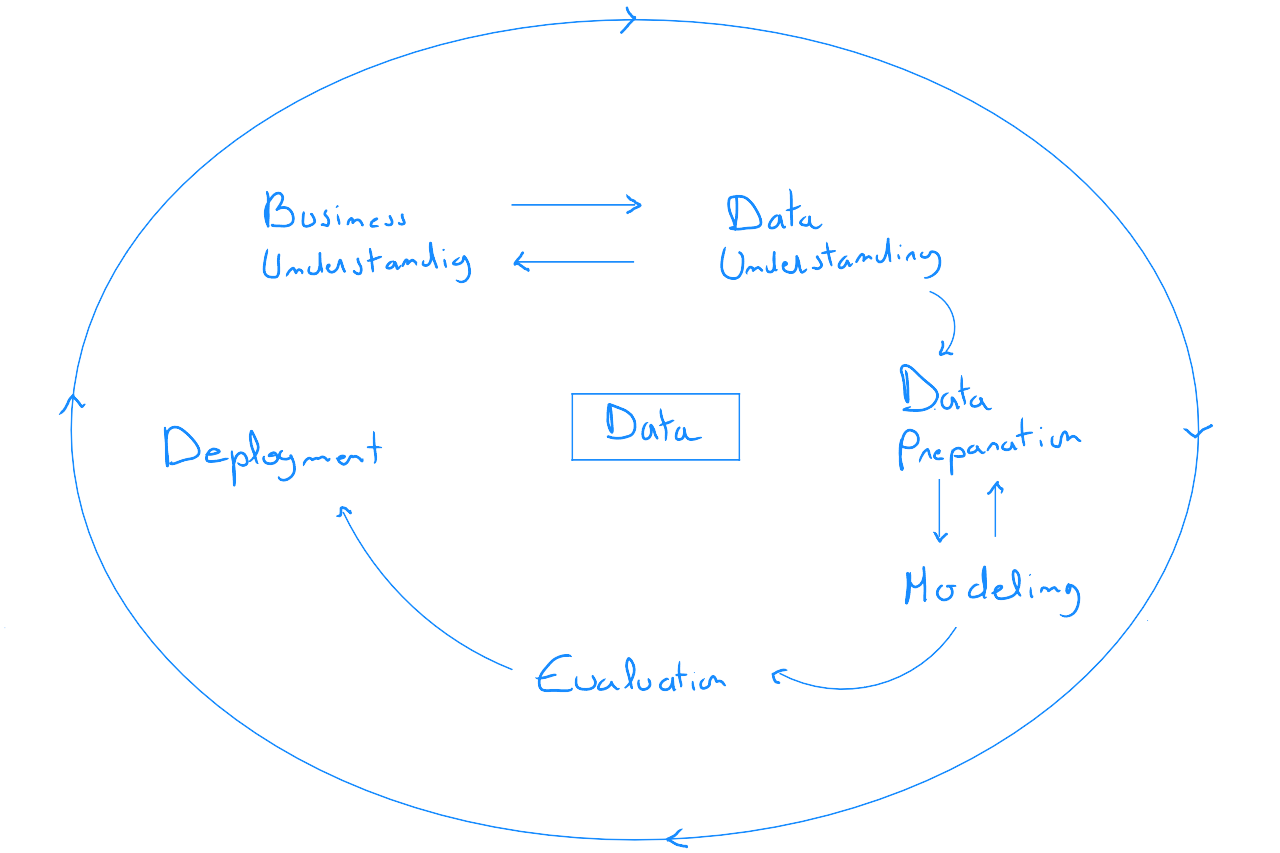
Step 1 : Business Understanding
This step corresponds to the project's purpose. It involves identifying the problems and defining the objectives that will ultimately evaluate the project and identifying available resources, whether personnel or equipment. Beyond defining the project boundaries, objectives, and key personnel, this step aims to provide the data scientist with all the business knowledge needed to contextualize the company's operations and align this understanding with the data generated by the daily activities of all departments.
To successfully carry out this mission, the data scientist must work closely with key stakeholders. The first sub-step of business understanding is to determine the organizational structure of the project.
It is recommended to form a steering committee, integrating key people from the company related to the project, including managers, members of the executive committee, and an internal project manager. Conducting a series of semi-structured qualitative interviews allows the data scientist to gather as much information as possible about the specific needs and operations of departments often organized in silos.
Indeed, when a company considers a data project, there is typically an initial need. However, it is crucial to understand the interferences between different departments in relation to the project and potentially uncover other unexpressed needs that could lead to future developments, impacting the project's approach.
The presence of executive members on the steering committee ensures 360 ° communication of the project and allows for rapid intervention in case of impediments during the development phases.
The project is often initiated with a goal that is too vague to evaluate its success properly. Therefore, it is recommended to rethink the main objective as a short-term strategy and to define a set of SMART objectives (Specific, Measurable, Achievable, Relevant, and Time-bound) that will be achieved through the implementation of specific tactics.
For example, if the project's goal is to predict the bed occupancy rate in a hospital to anticipate staffing needs, a SMART objective could be « to assess the available data sources, including a univariate descriptive analysis of all variables and sources, and identify areas for improvement in data collection within the first two months of the project ». The tactics represent how we will proceed. The first tactic could involve conducting qualitative interviews with the company's data architect, IT department, and external project managers involved in implementing the programs ; the second tactic could involve gathering the necessary information and access to extract the data ; the third tactic could be implementing an ETL (Extract-Transform-Load) process to access and visualize this information ; and finally, the fourth tactic could be creating a « state of play » report on the data sources.Defining SMART objectives and related tactics, along with the initial qualitative interviews, allows the data scientist to present a roadmap to the steering committee and validate the project's finalization criteria, a crucial element for defining the end of the intervention.
Step 2 : Data Understanding
The data understanding phase requires access to various sources - read-only - and the use of an ETL ( Extract, Transform, and Load ) tool, as well as the ability to perform data visualization to analyze the usability of the information. While many solutions exist, some of which are very expensive, it's also possible to use open-source tools such as Python and its numerous libraries.
Data understanding aims to strengthen the data scientist's knowledge of the information received during the qualitative interviews. It is not uncommon at this stage to return to the previous « business understanding » step to better understand certain aspects, as the data understanding process may reveal new insights.
The data understanding phase often concludes with a document - similar to documentation - summarizing the descriptive statistics of the different variables identified as relevant to the project, highlighting strengths and weaknesses, and providing recommendations for future improvements in data usage, often leading to internal « change management », meaning the modification of human processes.
Step 3: Data Preparation
Data preparation is the step that represents to % of the Data Scientist's work. This step corresponds to defining the algorithm, meaning all the necessary data transformation processes, and applying various statistical techniques to ultimately create a learning model.
This step includes all the processes covered in the chapter on variable engineering, as well as steps specific to data modeling, such as :
- Column and / or data record merging
- Data aggregation
- Replacing missing or outlier values
- Discretizing quantitative variables
- Digitizing discrete variables
- One-hot encoding
- Creating new variables
- Normalization or standardization
- Splitting the training and validation sets
- ...
Step 4 : Data Modeling
Modeling means applying one or more statistical techniques to « clean » data, as well as applying different versions of the algorithm to identify the best model - which implies the best configuration -.
Example : the data scientist might choose regression as the optimal technique given the data and test linear, 2nd-degree polynomial, 3rd-degree polynomial, and other configurations.The choice of model strongly depends on :
- The project's objective
- The type of data selected
- Specific modeling requirements related to a data type
As a Data Scientist, it's also important to work on the parameters : most statistical techniques, as part of the algorithm creation process, have numerous values or parameters that can be adjusted. For example, decision trees can be controlled by adjusting the tree depth, split thresholds, and many other values. Generally, models are created with default options, and then the parameters are fine-tuned.
Modeling is a highly iterative process in which many configurations are tested.
Step 5 : Evaluation
It's important not to confuse the CRISP-DM method's evaluation step with model evaluation. To obtain a learning model, the data scientist implements an algorithm. This algorithm consists of the processes needed to obtain the optimal model ( evaluated in the « Modeling » step - see Learning Concepts) -. These processes include applying and evaluating multiple statistical techniques and applying and evaluating several configurations of each technique ( parameters, sub-techniques, architecture, etc. ).
Evaluation involves comparing the project's results - specifically, the achievement of the SMART objectives set during the « business understanding » phase and the overall strategic goal that initiated the project -. This evaluation may also include a « retrospective » analysis to draw lessons from the experience.
Step 6 : Deployment
Deployment is the process of implementing the model's usage and ensuring its understanding by stakeholders. This phase includes users training. Deployment may also take the simple form of creating an automated task to regularly integrate the model's results into a data warehouse, where the information will be used by another process.
The preparation of a final report during the deployment phase makes the project closure tangible and generally includes the following points :
- A complete description of the initial business problems ;
- The report from the data exploration phase ;
- Project costs ;
- A summary of the completed sprints and key points ;
- Comments on any deviations from the initial project plan, as validated during sprint reviews ;
- Technical documentation of the algorithm ( all processes for obtaining the model ) ;
- The deployment plan ;
- Future recommendations