CRISP DM
CRISP-DM, Cross-Industry Standard Process for Data Mining, est une méthode / un modèle de processus mettant en avant le cycle de vie de tout projet data. Il s'agit d'un modèle proposé en 6 phases dont l'ordre des séquences n'est pas strictement fixe - mais suggérée - et offre en conséquence une flexibilité. Il est important de noter que l'application de ce modèle est généralement implémenté en parallèle de la méthode SCRUM. Le modèle CRISP-DM est une méthode d'approche générale, tandis que le cadre de travail SCRUM permet d'assurer sa bonne réalisation.
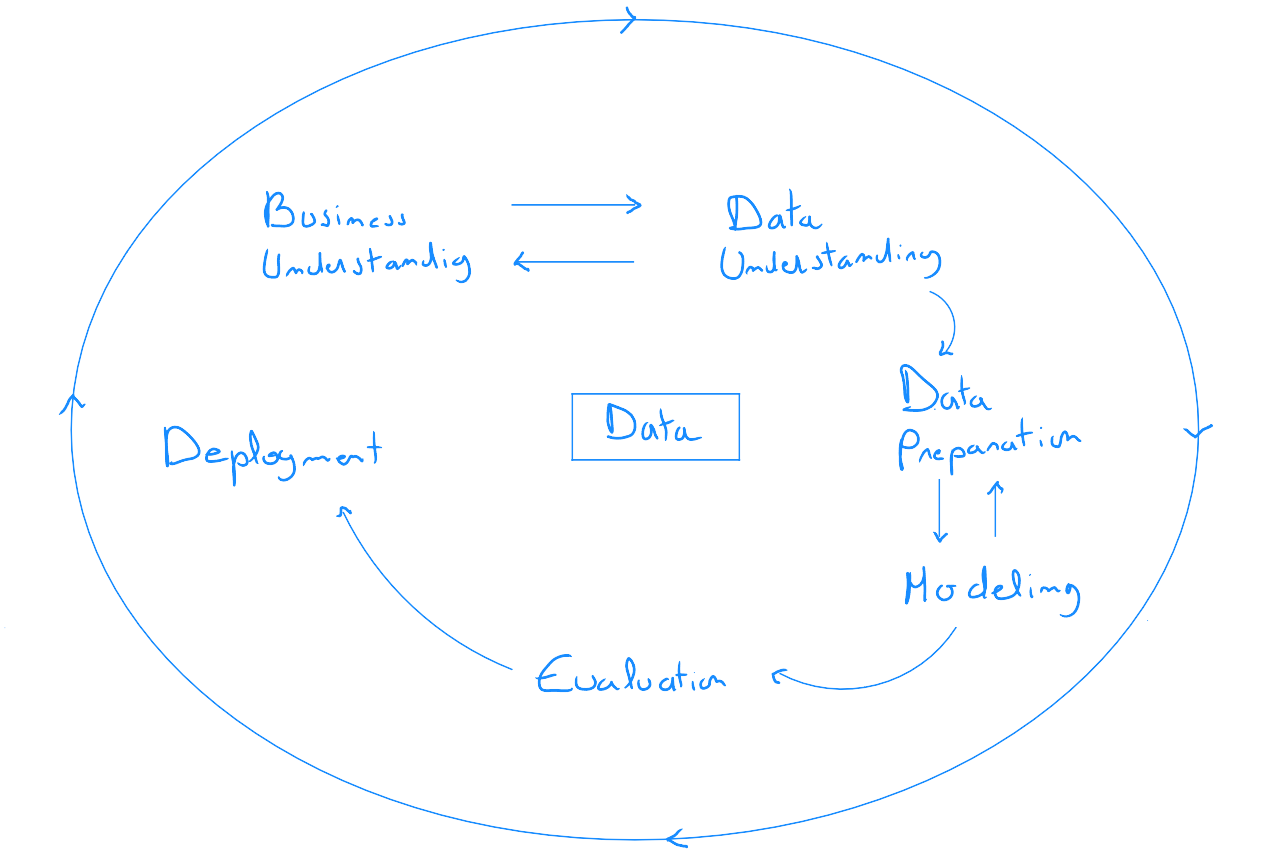
Étape 1 : compréhension métiers
Cette étape correspond à la raison d'être du projet. Il s'agit d'identifier les problèmes et définir les objectifs qui permettront d'évaluer in fine le projet et identifier les ressources disponibles ; qu'il s'agisse du personnel ou du matériel. Outre la définition des limites du projet, des objectifs, et des personnes ressources, cette étape vise à offrir toutes les connaissances métiers au data scientist afin de pouvoir contextualiser le fonctionnement business de l'entreprise et confronter cette dimension aux données générées par les activités quoitiennes de l'ensemble des départements.
Pour mener à bien sa mission, le data scientist doit s'entourer de personnes clés. La première sous-étape de la compréhension de l'entreprise consiste donc à déterminer la structure organisationnelle du projet.
Il est recommandé de constituer un comité de pilotage, intégrant les personnes clés de l'entreprise liées au projet, des personnes cadres ainsi que des membres du comité de direction et un responsable projet interne. La réalisation d'un ensemble d'entretiens qualitatifs semi-dirigés permet au data scientist de récolter un maximum d'informations sur les besoins et fonctionnements spécifiques des départements qui se trouvent trop souvent dans une situation d'organisation en silo.
En effet, lorsqu'une entreprise envisage un projet data, il existe bien entendu à la base un besoin mais il est fondamental de bien comprendre les interférences de différents départements au regard du projet et éventuellement déceler d'autres besoins non exprimés qui pourraient faire l'objet de développements futurs et par conséquent qui auraient un impact sur la manière de traiter le projet.
La présence de membres de la direction au sein du comité de pilotage permet d'assurer une communication 360° du projet et de pouvoir rapidement intervenir en cas d'impédiment dans les phases de développement.
Le projet est souvent initié par un objectif dont la formulation est souvent trop évasive pour pouvoir correctement évaluer sa réalisation. Par conséquent, il est recommandé de repenser l'objectif principal comme étant une stratégie court-terme, et de définir un ensemble d'objectifs SMART ( Spécifique, Mesurable, Atteignable, Relevant et ¨Timetable (avec échéance) ) qui seront atteints par la mise en place de tactiques spécifiques.
Par exemple, si l'objectif du projet est de prédire le taux d'occupation des lits d'un hôpital pour pouvoir anticiper les besoins en terme de ressources humaines, un objectif smart serait de «faire un état des lieux des sources de données à disposition comprenant une analyse descriptive univariée de l'ensembles des variables et sources et identifier les pistes d'amélioration du recueil d'informations endéans les deux premiers mois du projet». Les tactiques représentent les manières dont nous procéderons. La première tactique pourrait être la réalisation d'entretiens qualitatif avec le data architect de l'entreprise, le service informatique et les responsables projets d'organisations externe ayant participer à l'implémentation des programmes ; la seconde tactique serait le rassemblement des informations et accès pour pouvoir extraire les données ; la troisième tactique serait l'implémenter un processus ETL ( Extract-Transform-Load ) pour accéder et visualiser cette information et enfin la quatrième tactique serait la réalisation d'un rapport «état des lieux» des sources.La définition d'objectifs smart et de tactiques liées ainsi que les entretiens qualitatifs d'initiation du projet permettent au data scientist de présenter au comité de pilotage une roadmap et également de valider la définition de finalisation du projet, élément crucial pour définir la fin de l'intervention.
Étape 2 : compréhension des données
La phase de compréhension des données requiert un accès aux différentes sources - en lecture - et l'utilisation d'un outil de type ETL - Extract - Transform and Load ainsi que la possibilité de faire de la data visualisation afin de pouvoir analyser l'exploitabilité des informations. Il existe évidemment de nombreuses solutions - dont certaines sont très onéreuses -, mais il est également possible de s'en passer grâce à des outils de type open-source comme le langage python et ses nombreuses bibliothèques.
La compréhension des données vise à renforcer nos connaissances en tant que data scientist sur les informations reçues dans le cadre des entretiens qualitatifs. Il n'est pas rare, lors de cette étape, de revenir à l'étape précédente «compréhension métier» pour mieux comprendre certains aspects, dont la prise de connaissance des données met en lumière de nouvelles informations.
L'étape de compréhension des données est souvent finalisée par un document - type documentation - reprenant les statistiques descriptives des différentes variables à disposition et identifiées comme pertinentes au regard du projet ; mettant en avant les points forts et points faibles ; ainsi que des recommandations pour de futures améliorations des données à exploiter, qui souvent, mène à du « change management » en interne, c'est à dire, la modification de processus humains.
Étape 3 : préparation des données
La préparation des données est l'étape qui représente à % du travail du Data Scientist. Cette étape correspond en réalité à la définition de l'algorithme, c'est à dire tous les processus de transformation de données nécessaires ainsi que l'application de diverses techniques statistique pour arriver in fine à la création d'un modèle d'apprentissage.
Cette étape comprend notamment tous les processus abordés dans le chapitre sur l'ingénierie des variables, ainsi que des étapes propres à la modélisation de données, notamment :
- La fusion de colonnes et/ou des enregistrements de données
- L'agrégation de données'
- Le remplacement des valeurs manquantes ou aberrantes
- La discrétisation de variables quantitatives
- La numérisation des variables discrètes
- L'encodage one-hot
- La création de nouvelles variables
- La normalisation ou standardisation
- La séparation du set d'entrainnement et de validation
- ...
Étape 4 : modélisation des données
La modélisation signifie l’application d’une ou plusieurs techniques statistiques aux données « propres » ainsi que l'application de différentes versions de l'algorithme afin de pouvoir identifier le meilleur modèle - ce qui sous-entend la meilleure configuration de ce dernier -.
Le choix du modèle dépend fortement :
- De l'objectif du projet
- Du type de données sélectionnées
- Des exigences de modélisations particulières liées à un type de données
En tant que Data Scientist, il est important également de travailler sur les paramètres : la plupart des techniques de statistiques disposent dans le cadre des processus de création de l'algorithme, d'un grand nombre de valeurs ou de paramètres pouvant être ajustés. Par exemple, les arbres décision peuvent être contrôlés par l'ajustement de la profondeur de l'arbre, des seuils de séparations et de nombreuses autres valeurs. En général, les modèles sont créés avec les options par défaut, puis les paramètres sont affinés.
La modélisation est un processus fortement itératif dans laquelle de nombreuses configurations sont testées.
Étape 5 : Évaluation
Il est important de ne pas confondre l'étape d'évaluation de la méthode CRISP-DM avec l'évaluation d'un modèle. En effet, pour obtenir un modèle d'apprentissage, le data scientist implémente un algorithme. Cet algorithme est l'ensemble des processus permettant d'obtenir le modèle optimal ( et donc évalué à l'étape «Modélisation» - cf Notions d'apprentissage ). Ces processus comprennent l'application et l'évaluation de plusieurs techniques statistiques ainsi que l'application et l'évaluation de plusieurs configurations de chaque technique ( paramètres, sous-techniques, architecture,... ).
L'évaluation consiste à confronter les résultats du projet - c'est à dire l'atteinte des objectifs SMART fixés lors de l'étape «compréhension métiers» ainsi que l'atteinte de l'objectif stratégique général par lequel le projet a été initié. Cette évaluation peut comprendre également une analyse de type «rétrospective» afin de tirer des leçons de l'expérience.
Étape 6 : Déploiement
Le déploiement est le processus consistant à implémenter l'utilisation du modèle ainsi que sa compréhension par les parties prenantes. Cette phase intègre la formation des utilisateurs. Le déploiement peut également prendre la forme simple de la création d'une tâche automatique d'intégration des résultats du modèle de manière régulière dans un entrepôt de données, dont les informations seront par la suite utilisées par un autre processus.
L’élaboration d’un rapport final permet, dans la phase de déploiement, de rendre tangible la clôture du projet et reprend en général les points suivants :
- Une description complète des problèmes métiers initiaux;
- Le rapport de la phase d'exploration des données ;
- Les coûts du projet ;
- Un récapitulatif des sprints réalisés et points importants ;
- Des remarques sur tout écart par rapport au plan de projet initial et validé lors de sprints review ;
- Une documentation technique de l'algorithme ( tous les processus pour l'obtention du modèle ) ;
- Le plan de déploiement ;
- Des recommandations futures