Data modeling
As mentioned in the previous chapter, business intelligence refers to tools that offer ETL ( Extract - Transform - Load ) functionalities. A BI solution - a report containing multiple dashboards - allows connection to one or more data sources.
A data source is a database containing all the information from a software used daily by the company. Most databases are complex because they were not designed for analytical needs but rather to adapt to the continuous evolution of a company's operations. Consequently, a database regularly evolves as software also evolves and undergoes numerous modifications and adaptations throughout its usage.
For example, let's consider a hospital that builds a new annex for new treatments and uses various software daily : an accounting / purchasing ERP, a « patient record » software, an admission and billing software, a pharmacy software, etc. The creation of a new annex will impact all these software, whose database architecture will need to be modified.This modification can be minor ( adding a new care unit ) or major ( a change in legislation requiring that a database field be calculated in one way before a certain date and another way afterward ). It's also possible that adding the care unit to the tables corresponding to the old care units is not feasible due to some interdependencies between tables, and to prevent future evolution, from a certain date - the emergence of new care units - all information is directed to new tables, meaning that information must be retrieved from the old tables before a certain date and from the new tables afterward.
It's also likely that many variables ( table columns ) contain values considered aberrant or erroneous due to certain mandatory software flexibilities to meet specific business cases.
For example, a male patient who previously received maternity care ; a 30-year-old patient in a geriatric ward ; a patient aged 442 years ; etc.All data requires a thorough examination of available variables univariate statistical analysis as well as the preparation, transformation of information - feature engineering -.
In business intelligence, data modeling can be divided into two parts :
- Data transformation : transforming existing column values or creating new columns from existing ones.
- Simplifying the relational model into a star schema to ensure tool efficiency.
Data transformation
Data transformation involves applying functions to existing variables to either transform values ( correct values ) or create values from existing ones.
For example, in the hospital, in the « Patient » table, we find the columns « First Name » and « Last Name », and for specific data visualization needs, we create a new column « Patient Name », which combines the two aforementioned columns. This operation corresponds to the creation of a new variable based on existing variables. Another example, in the table that records care units ( CU ), we find in one data source the values CUFA1 and CUFA2, while in another data source, we only find the value CUFA. The latter term CUFA resulted from the merging of care units CUFA1 and CUFA2 following a new funding legislation, but one of the software ( admission ) was not updated. Therefore, we will use a formula to transform the existing values and instruct the software to replace the CUFA1 and CUFA2 values with CUFA from a certain date.Data transformation can be done either through a code editor - integrated into most tools - where the data architect uses a language specific to the tool to apply these modifications, or there are also « low code » interfaces in most tools that allow users to make many changes through a user-friendly interface with specific selections. Modifications at the BI tool level do not impact the data source ; these are code instructions that execute in the BI tool during data reload - reading the original data -.
Data transformation also includes a set of minor modifications - formatting - such as renaming a variable, changing the data type, modifying formatting, extracting part of the information, etc.
Star schema
When a data architect works on creating a business intelligence application on one or more data sources, it's their duty to ensure the efficiency of the application, and they must consequently review the relational schema of the tables. It is important to understand that by default, when a user makes a selection in a Dashboard - filters the information - the tool reacts instantly, meaning that the visuals adjust to the selection.
The reason is simple : the query formed by the user is not sent to the data source but directly to the BI tool which, during data loading ( extraction from one or more sources ), creates a copy of the information. Therefore, the user is no longer querying the original data source but the data schema in the tool. This copy of the information is made according to specific schedules depending on the need for data refreshment ( once a day, every hour, every 5 minutes ). A user can also run the script at any time to update the information, meaning loading the new data recorded in the database since the last copy. Of course, copying information into the tool's memory is the default state, but in some cases—particularly for tables with large amounts of information ( fact tables ) - it is possible to be directly connected to the data source and get continuous refreshment for that table -.
The first element that promotes the responsiveness of a business intelligence tool is that the query does not directly access the data source. The second element is that the data architect's mission is to simplify the relational schema between the tables and move towards what is called a datamart - a star schema -.
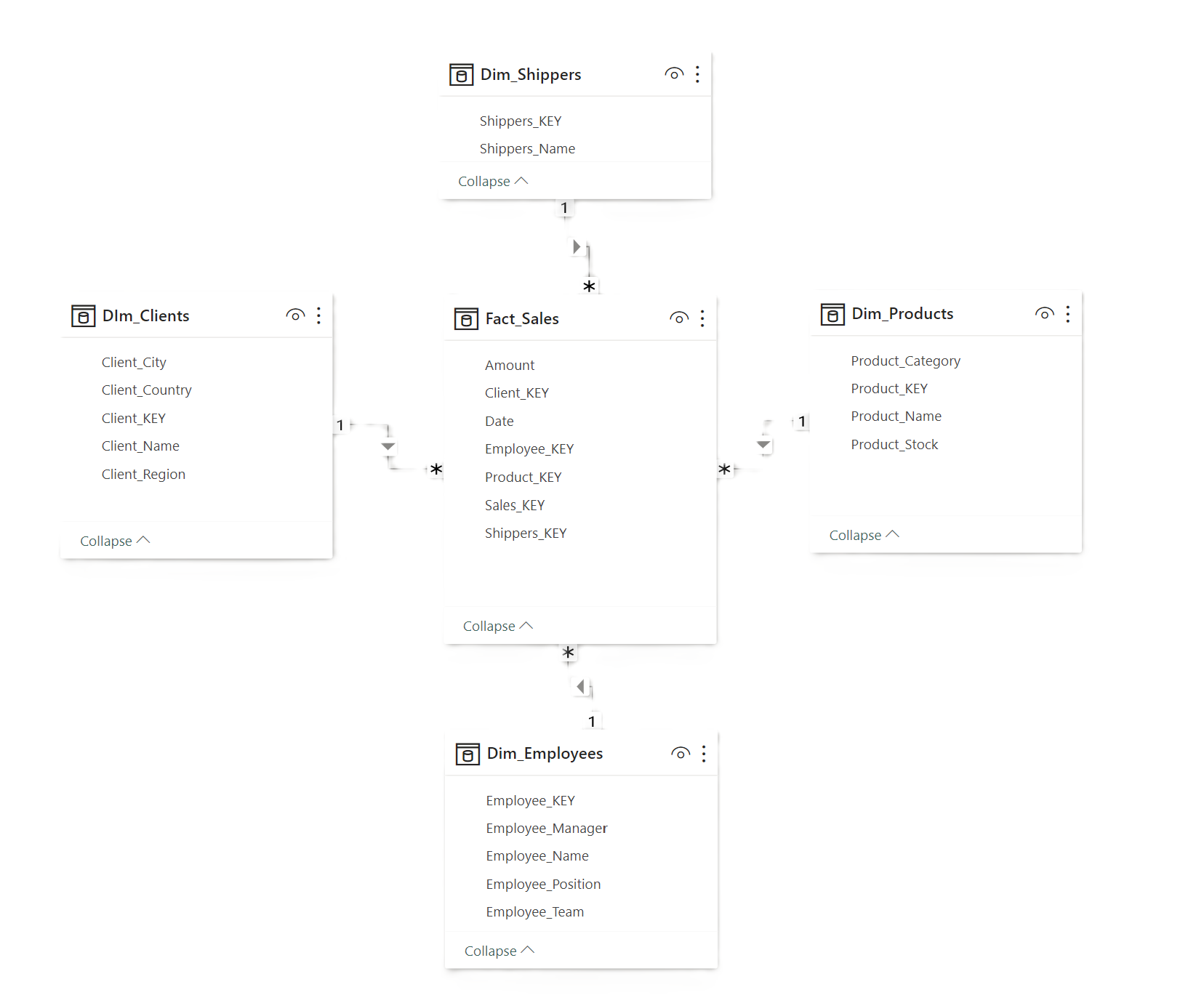
Transactional vs dimensional tables
The star schema is the most commonly used approach in business intelligence and also in data warehouses to promote the efficiency of data analysis tools. The star schema involves creating a datamart, a simplified schema where we find :
- A fact table - transactional table - which is at the center of the schema. This is the main table containing all the events or transactions. A fact table is easily identifiable as it generally contains many rows for a limited number of columns, which are mainly key columns related to dimension tables and measurement columns ( quantitative variables ) as well as a temporal notion - date column ( or timestamp ) -.
- Dimension tables which contain one or more key columns as well as dimensional information beyond the key. Dimension tables generally have many columns but few rows and are mainly used to filter the measures.
The relationship between a dimension table and a fact table is one-to-many ( 1 - * ). A single record in the dimension table is linked to multiple records in the fact table.
Normalization & Denormalization
A fact table is normalized : normalization describes data stored to reduce repetitive information. For example, a product table contains the product key along with many columns related to information about that key ( product name, product category, etc. ). In the fact table, it is unnecessary to repeat information related to the key that goes beyond this information. The key alone is sufficient to link all the information. Thus, the table is said to be normalized - the number of columns is reduced to the strict minimum necessary -.
Conversely, a dimension table is denormalized : denormalization describes data stored with all information taken into account. The product dimension table contains the product key along with all fields beyond that key, such as the product name, category, etc.
Normalized fact table (sales)
| Sales_Key | Product_Key | Customer_Key | Date | Quantity | Amount |
|---|---|---|---|---|---|
| 1 | 101 | 1 | 2024-01-01 | 2 | 100 |
| 2 | 102 | 2 | 2024-02-15 | 1 | 50 |
| 3 | 101 | 1 | 2024-03-20 | 3 | 150 |
| 4 | 103 | 3 | 2024-04-10 | 5 | 250 |
Denormalized fact table (sales)
| Sales_Key | Prod_Key | ProductName | Category | Cust_Key | CustomerName | City | Date | Quantity | Amount |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 101 | Product A | Electronics | 2 | John Doe | New York | 2024-01-01 | 2 | 100 |
| 2 | 102 | Product B | Clothing | 1 | Jane Smith | London | 2024-02-15 | 1 | 50 |
| 3 | 101 | Product A | Electronics | 3 | John Doe | New York | 2024-03-20 | 3 | 150 |
| 4 | 103 | Product C | Books | 5 | Alice Brown | Paris | 2024-04-10 | 5 | 250 |
A data architect will always load table by table from a data source to conceptualize the star schema, which means grouping transactional information into a central - unique - table, normalizing this transactional table, and adding a set of denormalized dimension tables to the model.
Table Merging
To achieve the creation of a star schema, i.e. grouping ( merging) a set of tables into a limited number in a simplified model, the data architect has two options :
- Apply a join function to add the columns of a table B to a table A based on the values of one or more common key columns. This is the JOIN function, which can take different prefixes ( outer, inner, left, right ).
- Apply a concatenation function ( horizontal axis - also known as UNION ) to add the records of a table X below the records of a table Y based on ( generally ) several ( or all ) common columns.
Join
Joining adds one or more columns from a table B into a table A, provided that both tables have one or more common columns and common values within those columns.
Below we find two tables - separated in the data model - the products table ( products related to Yoga practice ) and the categories table. We want to group these tables ( merge them ), i.e. integrate the CategoryName from the categories table into the products table. Both tables have a common column ( CategoryID ) with most values in common.
We notice, in the tables below, that the products table contains a product ( Yoga Perfume ) linked to a CategoryID of 6 that does not exist in the categories table, and we see that we have CategoryID 5 in the categories table, for which we have no related products in the products table.
| ProductID | Product | CategoryID |
|---|---|---|
| 64 | Mat Green | 1 |
| 65 | Mat Blue | 1 |
| 66 | Mat Cleaner | 2 |
| 67 | Yoga Bricks | 2 |
| 68 | Mat Straps | 3 |
| 69 | Mat Bag | 3 |
| 70 | Trousers | 4 |
| 71 | Legging | 4 |
| 72 | Yoga Perfume | 6 |
| CategoryID | CategoryName |
|---|---|
| 1 | Yoga Mat |
| 2 | Yoga Accessories |
| 3 | Yoga Mat Bag |
| 4 | Women Yoga Clothes |
| 5 | Men Yoga Clothes |
Full Outer Join
By default, if we want to merge the two tables, the merge function will include in the resulting table ( the final table, which will be unique ) all the values from table A and all the values from table B ; this is called an Outer Join - no information is lost due to the merge -.
The Python function comes from the pandas library (pd.merge)
import pandas as pd
# Full outer join
df_final = pd.merge(df_products, df_categories, on='CategoryID', how='outer')
# Filling missing values with 'N/A'
df_final.fillna('N/A', inplace=True)
df_final
The result is the following table :
| ProductID | Product | CategoryID | CategoryName |
|---|---|---|---|
| 64 | Mat Green | 1 | Yoga Mat |
| 65 | Mat Blue | 1 | Yoga Mat |
| 66 | Mat Cleaner | 2 | Yoga Accessories |
| 67 | Yoga Bricks | 2 | Yoga Accessories |
| 68 | Mat Straps | 3 | Yoga Mat Bag |
| 69 | Mat Bag | 3 | Yoga Mat Bag |
| 70 | Trousers | 4 | Women Yoga Clothes |
| 71 | Legging | 4 | Women Yoga Clothes |
| 72 | Yoga Perfume | 6 | N/A |
| N/A | N/A | 5 | Men Yoga Clothes |
Inner Join
The Inner prefix removes from the final table all records that are not common to both tables. This means that all CategoryID key values not present in both tables will be excluded. Consequently, if we have one or more products whose category does not exist in the categories table, and one or more categories in the categories table for which we have no CategoryID in the products table, these records will be omitted.
For example, in our case, the final table will not include ProductID 72 - which is not linked to any category - nor Category 5, which is not present in the products table.| ProductID | Product | CategoryID |
|---|---|---|
| 64 | Mat Green | 1 |
| 65 | Mat Blue | 1 |
| 66 | Mat Cleaner | 2 |
| 67 | Yoga Bricks | 2 |
| 68 | Mat Straps | 3 |
| 69 | Mat Bag | 3 |
| 70 | Trousers | 4 |
| 71 | Legging | 4 |
| 72 | Yoga Perfume | 6 |
| CategoryID | CategoryName |
|---|---|
| 1 | Yoga Mat |
| 2 | Yoga Accessories |
| 3 | Yoga Mat Bag |
| 4 | Women Yoga Clothes |
| 5 | Men Yoga Clothes |
We specify the « how » in the Python function, and this time it's an inner join.
import pandas as pd
# Inner join
df_final = pd.merge(df_products, df_categories, on='CategoryID', how='inner')
df_final
And We obtain the following table :
| ProductID | Product | CategoryID | CategoryName |
|---|---|---|---|
| 64 | Mat Green | 1 | Yoga Mat |
| 65 | Mat Blue | 1 | Yoga Mat |
| 66 | Mat Cleaner | 2 | Yoga Accessories |
| 67 | Yoga Bricks | 2 | Yoga Accessories |
| 68 | Mat Straps | 3 | Yoga Mat Bag |
| 69 | Mat Bag | 3 | Yoga Mat Bag |
| 70 | Trousers | 4 | Women Yoga Clothes |
| 71 | Legging | 4 | Women Yoga Clothes |
Left Join
The left prefix is the most commonly used. It loads all the records from table A but keeps only the common key values from table B. This prefix thus removes from the final table all records from table B whose CategoryID key values do not exist in table A. Consequently, if we have one or more categories that do not exist in the products table, these rows will not be included in the final table.
For example, in our case, the final table will not contain Category 5, which is not linked to any product, but it will keep ProductID 72, which is not linked to any category.| ProductID | Product | CategoryID |
|---|---|---|
| 64 | Mat Green | 1 |
| 65 | Mat Blue | 1 |
| 66 | Mat Cleaner | 2 |
| 67 | Yoga Bricks | 2 |
| 68 | Mat Straps | 3 |
| 69 | Mat Bag | 3 |
| 70 | Trousers | 4 |
| 71 | Legging | 4 |
| 72 | Yoga Perfume | 6 |
| CategoryID | CategoryName |
|---|---|
| 1 | Yoga Mat |
| 2 | Yoga Accessories |
| 3 | Yoga Mat Bag |
| 4 | Women Yoga Clothes |
| 5 | Men Yoga Clothes |
We specify "how" in the Python function, and this time it's a left join.
import pandas as pd
# Left join
df_final = pd.merge(df_products, df_categories, on='CategoryID', how='left')
# Filling missing values with 'N/A'
df_final.fillna('N/A', inplace=True)
df_final
And we obtain the following table :
| ProductID | Product | CategoryID | CategoryName |
|---|---|---|---|
| 64 | Mat Green | 1 | Yoga Mat |
| 65 | Mat Blue | 1 | Yoga Mat |
| 66 | Mat Cleaner | 2 | Yoga Accessories |
| 67 | Yoga Bricks | 2 | Yoga Accessories |
| 68 | Mat Straps | 3 | Yoga Mat Bag |
| 69 | Mat Bag | 3 | Yoga Mat Bag |
| 70 | Trousers | 4 | Women Yoga Clothes |
| 71 | Legging | 4 | Women Yoga Clothes |
| 72 | Yoga Perfume | 6 | N/A |
Right Join
The right prefix is the least used. It loads all the records from table B but keeps only the common key values from table A. This prefix thus removes from the final table all records from table A whose CategoryID key values do not exist in table B. Consequently, if we have one or more products that exist in the products table but are not linked to any category in the categories table, these rows will not be included in the final table.
For example, in our case, the final table will not contain Product 72, which is not linked to any category, but it will keep CategoryID 5, which is not linked to any product.| ProductID | Product | CategoryID |
|---|---|---|
| 64 | Mat Green | 1 |
| 65 | Mat Blue | 1 |
| 66 | Mat Cleaner | 2 |
| 67 | Yoga Bricks | 2 |
| 68 | Mat Straps | 3 |
| 69 | Mat Bag | 3 |
| 70 | Trousers | 4 |
| 71 | Legging | 4 |
| 72 | Yoga Perfume | 6 |
| CategoryID | CategoryName |
|---|---|
| 1 | Yoga Mat |
| 2 | Yoga Accessories |
| 3 | Yoga Mat Bag |
| 4 | Women Yoga Clothes |
| 5 | Men Yoga Clothes |
We specify the « how » in the python function, and this time it's a right.
import pandas as pd
# Right join
df_final = pd.merge(df_products, df_categories, on='CategoryID', how='right')
# Filling missing values with 'N/A'
df_final.fillna('N/A', inplace=True)
df_final
And we obtain the following table :
| ProductID | Product | CategoryID | CategoryName |
|---|---|---|---|
| 64 | Mat Green | 1 | Yoga Mat |
| 65 | Mat Blue | 1 | Yoga Mat |
| 66 | Mat Cleaner | 2 | Yoga Accessories |
| 67 | Yoga Bricks | 2 | Yoga Accessories |
| 68 | Mat Straps | 3 | Yoga Mat Bag |
| 69 | Mat Bag | 3 | Yoga Mat Bag |
| 70 | Trousers | 4 | Women Yoga Clothes |
| 71 | Legging | 4 | Women Yoga Clothes |
| N/A | N/A | 5 | Men Yoga Clothes |
Concatenation
Applying a concatenation function ( horizontal axis - also known as UNION ) consists of adding new records from table X to existing records in table Y. The new records are integrated into the table as new rows. Concatenation is generally applied between two tables that have an almost identical structure.
| ProductID | Product |
|---|---|
| 64 | Mat Green |
| 65 | Mat Blue |
| 66 | Mat Cleaner |
| 67 | Yoga Bricks |
| 68 | Mat Straps |
| 69 | Mat Bag |
| 70 | Trousers |
| 71 | Legging |
| 72 | Yoga Perfume |
| ProductID | Product | Code |
|---|---|---|
| 73 | Mat Red | 654983211 |
| 74 | Sandbag | 953625923 |
| 75 | Cylindrical Bolster | 278534109 |
Here is the python code :
import pandas as pd
df_final = pd.concat([df1, df2], ignore_index=True)
df_final = df_final.fillna('NA')
df_final
df_final
And we obtain the following table :
| ProductID | Product | Code |
|---|---|---|
| 64 | Mat Green | N/A |
| 65 | Mat Blue | N/A |
| 66 | Mat Cleaner | N/A |
| 67 | Yoga Bricks | N/A |
| 68 | Mat Straps | N/A |
| 69 | Mat Bag | N/A |
| 70 | Trousers | N/A |
| 71 | Legging | N/A |
| 72 | Yoga Perfume | N/A |
| 73 | Mat Red | 654983211 |
| 74 | Sandbag | 953625923 |
| 75 | Cylindrical Bolster | 278534109 |